The field of data science is rapidly growing and evolving. And in the next decade, new ways of automating data collection processes and deriving insights from data will boost workflow efficiencies like never before.
There’s no better way to understand the changing nature of data science than by examining some real-life examples. Whether you’re thinking about a career in data science, or if you’re a practicing data science looking to see where the field is heading, we’ve got you covered. Below, we’ll explore seven case studies from the world of data science, all of which reveal the field’s potential for both business and research.
Why Are Data Science Case Studies Important?
When learning about data science, it’s important to have case studies to learn from and use as examples. Case studies are helpful tools when you want to illustrate a specific point or concept. They can be used to show how a data science project works in real life, or they can be used as an example of what to avoid.
Data science case studies help students, and entry-level data scientists understand how professionals have approached previous challenges. They give you ideas for how to approach your own challenges and ultimately aim for innovation.
7 Top Data Science Case Studies
Here are 7 top case studies that show how companies and organizations have approached common challenges with some seriously inventive data science solutions:
Geosciences
Data science is a powerful tool that can help us to understand better and predict geoscience phenomena. By collecting and analyzing data, we can make data-driven decisions about how to respond to natural disasters, such as hurricanes or earthquakes.
We can also use data science to collect information about the earth’s climate, which helps us determine how quickly it will change over time and how we might mitigate some of those changes.
Tsunami Early Warning Method From Stanford University
This early warning system can provide communities with valuable information to help geoscientists prepare for and mitigate the impacts of a potential tsunami. Even so, this method has its drawbacks. Tides, currents, temperature, and salinity changes can alter the data generated by the sensors, which can result in false positives.
Data scientists are improving the warning system’s accuracy by using machine learning algorithms to detect and alert communities of possible tsunamis. This system also has implications for climate change research and disaster relief. By using data science to better understand climate change’s effects, scientists can develop strategies to reduce the risk of natural disasters and help communities better prepare for and respond to them.
Healthcare
Data science and machine learning technologies are revolutionizing the medical industry. With the help of these tools, doctors can detect even the slightest changes in the patient’s health indicators and predict potential diseases before they become more severe.
Google’s LYNA for Metastatic Breast Cancer Detection

Pathology is essential for diagnosing cancer, and its microscopic examination of tumors is the gold standard. This evaluation is critical in determining prognosis and treatment decisions. One key aspect of this process is detecting cancer that has metastasized from the primary site to nearby lymph nodes.
The accuracy and timeliness of identifying nodal metastases in breast cancer majorly impact treatment decisions, including radiation therapy, chemotherapy, and the potential surgical removal of additional lymph nodes.
Unfortunately, studies have shown that around 25% of metastatic lymph node staging classifications are revised upon a second pathologic review. Additionally, the detection sensitivity of small metastases on individual slides can be as low as 38% when reviewed under time constraints.
This is where data science comes into play. Google’s LYmph Node Assistant (LYNA) achieved significantly higher cancer detection rates than previously reported. LYNA was applied to pathology slides from the Camelyon Challenge and an independent dataset provided by the Naval Medical Center San Diego. This additional dataset improved the representation of the diversity of slides and artifacts seen in routine clinical trials.
The LYmph Node Assistant was incredibly successful in both datasets, correctly distinguishing slides with metastatic cancer from those without cancer 99% of the time. It could even identify areas of concern within each slide that was too small to be detected by pathologists. This could help them greatly, as LYNA could highlight these areas of concern for pathologists to review and make the final diagnosis faster than ever.
Logistics
Data science has become a powerful tool for logistics companies to optimize their operations. Namely, it can be used to determine the most efficient delivery routes, manage fuel usage at the most cost-effective times of day, and make more accurate predictions about supply and demand. And all of these factors help logistics companies save time and money.
UPS’s Network Planning Tools (NPT)

Network Planning Tools (NPT) is an app developed by UPS used to help navigate and efficiently move packages worldwide, despite any weather conditions. NPT utilizes machine learning to process and analyze large amounts of real-world data, allowing UPS to view all its facilities, divert its packages around storms, or move a large shipment quickly.
UPS has developed NPT to comprehensively view the organization’s operations. These tools are designed to give an overview of activities at UPS facilities worldwide and package volume and distribution across its pickup and delivery network. It also enables UPS to get detailed information about shipments in transit, such as their weight, volume, and delivery deadlines.
By utilizing NPT, UPS can take advantage of various features such as routing shipments to the facilities with the most capacity, moving volume to lower-cost transportation modes, preemptively rerouting packages to alternative lanes to avoid unexpected costs and delays due to storms or other events, and creating forecasts about package volume and weight based on detailed analysis of historical data.
Like the best data science tools, NPT empowers humans to make better decisions. When a package reroutes, the app notifies an engineer in the new location about the revised plan. The engineer then evaluates various options and takes action, potentially rerouting the package based on new information. This human-driven decision gets updated in the app, helping it learn from human oversight and get smarter about routing plans. NPT also checks the engineer’s choice to ensure that it has the desired result. This allows NPT’s algorithm to improve and make smarter decisions when routing packages.
Banking

Data science has revolutionized the way businesses detect fraudulent activities. It plays a crucial role in collecting, summarizing, and predicting customer databases to identify fraudulent activity accurately.
J.P. Morgan’s Use of NLP and AI
J. P. Morgan and APG Asset Management have recently studied how data science can improve how portfolio managers and research analysts utilize information. By using data from the European Central Bank, they have been able to pinpoint multiple use cases for this technology in developing new user interfaces. Individual company employees collaborated through a single data repository to observe each other’s progress and build a prototype AI application.
This project may have overall implications for the banking industry, not just for J.P. Morgan. For example, an AI-enabled dashboard could display the most important market trends for the manager to show to their client, resulting in higher customer satisfaction as they can better understand their investments.
Contract Intelligence (COiN)
J.P. Morgan also uses machine learning and artificial intelligence to develop a new software called COIN (Contract Intelligence). The tool reviewed thousands of the bank’s credit contracts, utilizing image recognition to recognize patterns in these agreements. This technology employs unsupervised learning, enabling the algorithm to classify clauses into one of about 150 different “attributes” of credit contracts. For example, the algorithm can note specific patterns based on clause wording or location in the agreement.
JPMorgan’s investment in data science is motivated by the benefits of cost savings. The software can review contracts in seconds, a process that previously took lawyers over 360,000 man-hours. Not only does the algorithm save time and money. It also improves the accuracy of the process. Compared to human lawyers, the accuracy of COIN is significantly greater. Thus, the bank’s investment is not only about cutting costs but also about increasing quality.
E-Commerce
Data science in e-commerce is revolutionizing the way companies do business, as it allows them to collect and analyze valuable information. Innovative technologies are also being used to boost profits with personalized recommended lists, dynamic pricing, and the ability to predict customers’ buying behavior. This gives e-commerce businesses an edge over their competitors and helps them stay ahead of the curve in an increasingly competitive market.
Personalized recommendations are an important part of the modern e-commerce experience. A study conducted by Epsilon shows that 80 percent of consumers are more likely to purchase from a brand that delivers personalized experiences. They can be used to show products that customers have shown interest in or to suggest products that are similar to those they’ve viewed in the past.
Amazon’s Recommendation Engine
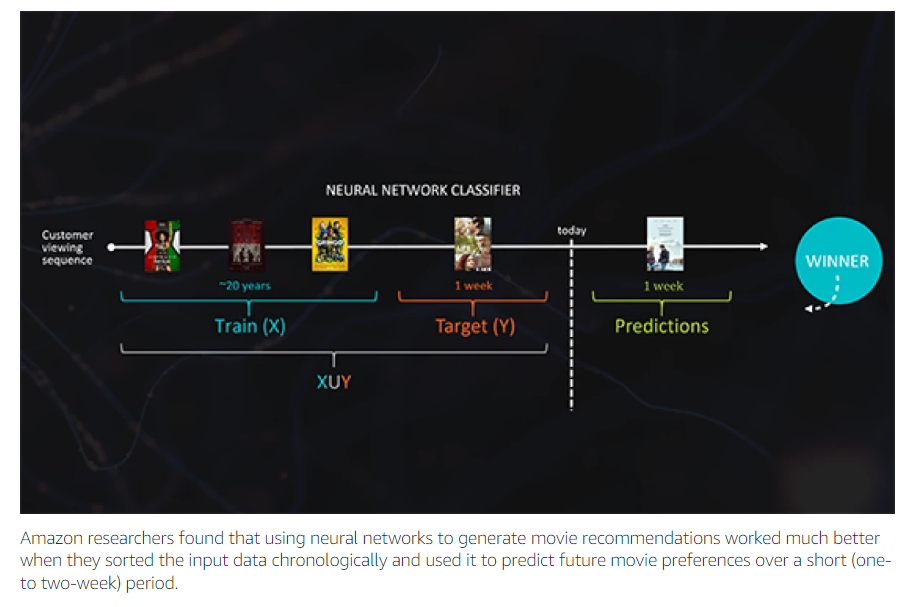
The Amazon recommendation engine is one of the most well-known examples of this type of technology. It uses machine learning to match users with items similar to those they’ve previously interacted with. It does this by analyzing what types of items a user purchases, browses, watches, or listens to. It then matches other users with similar interactions with similar items and recommends them based on their preferences.
As “recommendations” are made based on a user’s past interactions and interests, they are very likely to increase Amazon’s bottom line as people will find the recommended product interesting and will be more likely to buy it. But that statistic just scratches the surface regarding the power of data science in e-commerce. McKinsey noted that 35% of all items purchased from Amazon and 75% of what people watch on Netflix come from product recommendation engines.
Agriculture

Agriculture has always been an unpredictable business. But data science is changing how farmers manage their businesses by providing access to information they didn’t have before. It helps them optimize their operations and make more money by allowing them to cut back on waste and increase productivity.
Farmers can now use technology to make better decisions about what crops should be grown in certain areas, which animals are most profitable for them to raise, and how much water is needed for certain plants at specific times of the year.
Watson Decision Platform for Agriculture
IBM is working on ways to help improve farm productivity through artificial intelligence and machine learning. They are developing an AI system called the Watson Decision Platform for Agriculture. It will provide farmers with data about their crops and soil conditions to make more informed decisions about how to grow their crops.
This machine learning model can be applied to any location, regardless of weather conditions or growing conditions, and can be used to determine yields for past growing seasons, which is critical for validating agriculture insurance claims and risk, optimizing supply-and-demand chain logistics, and even predicting commodity prices.
In addition, the API uses weather forecast details to predict the risk of corn pests and disease outbreaks as well as the likelihood of spore transport. Farmers can use this information to reduce pesticide usage and take preventive or curative measures to avoid unexpected yield loss.
Transportation
Data science can be used to improve transportation operations in several ways:
- Delivery path optimization, which reduces freight costs by evaluating various delivery paths and determining the most cost-effective
- Dynamic price matching, to match supply to demand and maximize profits
- Warehouse optimization, to maximize the efficiency of warehouse operations
- Forecasting demand, to anticipate customer needs and prepare for them in advance
Uber’s Gairos for Dynamic Pricing

Uber, perhaps the most disruptive company in the transportation industry, has leveraged this with the development of Gairos, a real-time data processing, storage, and query language platform. This platform facilitates streamlined and efficient data exploration at scale, enabling teams to gain insights into the Uber Marketplace.
Through the use of Gairos, Uber can gain various insights that are crucial to its operations. For example, dynamic pricing leverages demand and supply data to calculate surge multipliers at specific locations and times. Driver movement utilizes real-time demand and supply data to suggest surge and carbon-friendly routes for drivers.
Get To Know Other Data Science Students

Mengqin (Cassie) Gong
Data Scientist at Whatsapp

Jonas Cuadrado
Senior Data Scientist at Feedzai

Haotian Wu
Data Scientist at RepTrak
Data Science Case Studies FAQs
We’ve got the answers to your most frequently asked questions:
How Can You Use a Case Study About Data Science?
Case studies can be an invaluable resource for students to gain an understanding of the data science field. Such studies can provide insights into the real-world application of data science, as well as the necessary skills like programming language skills and statistical models.
How Do You Write a Data Science Case Study?
First, you should identify the problem you want to solve. This can be as simple as “I want to analyze my customer base” or more complex, such as “I want to predict which customers will respond best to this particular ad campaign.”
You’ll need to write a hypothesis that explains how your proposed solution will work. This should be clear, concise, and easy to understand.
Then you’ll need to describe your data set—what exactly are you working with? How many records are there? What kind of information do they contain? Are there any missing values?
Next, describe how you processed your data before applying machine learning methods. Did you use any preprocessing steps? Did you normalize your data? Did you remove outliers? These are all crucial steps you must include in your case study if you want others who read it later to understand what happened during processing.
How Do Data Science Case Studies Impact the Industry?
Data science case studies highlight the work done by practitioners, and they can be used to educate new and existing data scientists on how to approach problems.
Case studies also help companies determine which type of data science teams they should create and how those teams should be structured. By providing valuable information about what kinds of data science projects are most successful in the real world, they help companies develop business strategies for their future collection of projects.
Since you’re here…Are you interested in this career track? Investigate with our free guide to what a data professional actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp which will help you land a job or your tuition back!