
Data wrangling is a process used often by data analysts when they begin working with new sets of ra’ or ‘Deutschland’ only returns entries matching that text striw data. You may have heard the term before, or you may have heard it referred to as data munging. In the simplest terms, to wrangle data is to organize and standardize its format so it can be analyzed by software data processing.
It’s an important task in the day of a data scientist, so learning about data wrangling is crucial if you want to enter a career in data science or data analytics. In fact, the Anaconda State of Data Science 2020 report found that data scientists spend around 26% of their time wrangling data.
This guide will fill you in on what data wrangling is, what its benefits are, how it works, and when you should use it—everything you need to start wrangling some data yourself.
What Is Data Wrangling?
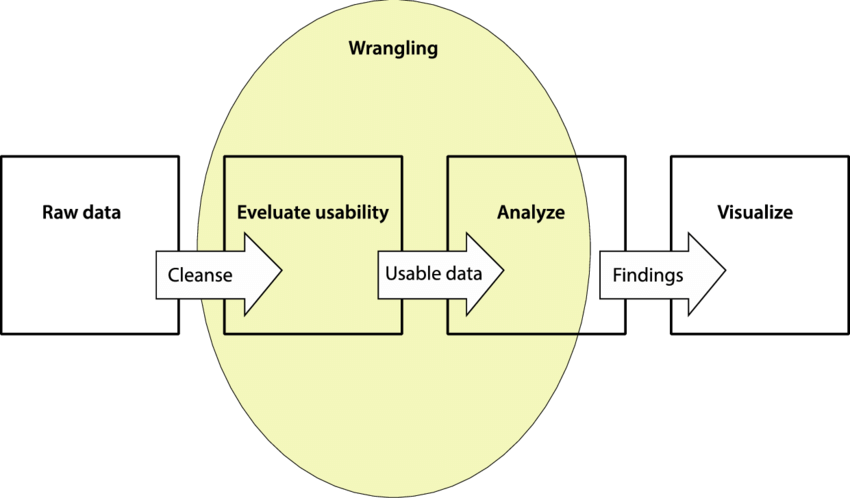
When data analysts and data scientists analyze data, they code models that will read through the data and return entries that match their requirements.
However, computers don’t read information in the way that we do. To a computer, the words Germany, DE, and Deutschland are simply different text strings with no apparent relation to each other. To humans, however, each of these words refers to the same country.
As an example, imagine that you have three different pieces of data about Germany attached to these entries. If you query a database for all data on Germany, you would only get back the one entry that exactly matches the text string “Germany.”


The above two screenshots show that querying for ‘Germany’ or ‘Deutschland’ only returns entries matching that text string, rather than all entries matching the country of Germany.

Here, you can see that in order to return all applicable entries, the query would have to include every name format used within the data set. This would be annoying with smaller data sets and impossible with large ones.
This is one kind of problem data wrangling takes care of. When you wrangle data, you standardize its format so the algorithms can read it and then return the information you want.
What Are the Goals?
The goal of data wrangling is to first take data in its raw form that has come from different sources and in different formats. The next step is to organize, clean, and standardize it. This means deleting duplicates, standardizing date formats and abbreviations, and checking for errors so the data can be used for analysis.
What Are the Benefits?
Data wrangling is a necessary step in the data science process that enables you to conduct that analysis. If your data is non-standardized and fraught with errors and duplicates, any query you make of it will return incomplete and incorrect sets of data that would produce invalid outcomes when analyzed.
Get To Know Other Data Science Students

Melanie Hanna
Data Scientist at Farmer's Fridge

Diana Xie
Machine Learning Engineer at IQVIA

Hastings Reeves
Business Intelligence Analyst at Velocity Global
What Are the Challenges?
The main challenges with data wrangling are the time it takes and the limited amount of work that can be automated. While many Python libraries exist that can help streamline the wrangling process for common problems (i.e. standardizing date formats), the reality is that there will always be bespoke problems that require manual correction.
Only a human can comprehend the semantic meaning of a non-standard format and change it into standard syntax that software can organize.
How Does Data Wrangling Work?
Next, we’ll go into the details of data wrangling and how it actually achieves the goals and benefits outlined above.
What Tools Should Be Used in Data Wrangling?

In terms of wrangling tools, data analysts write scripts and use scripting libraries to wrangle their data. Python is a popular example of a scripting language that is used for data wrangling, and writing data structures and algorithms. It focuses on readability and has a large community that has created thousands of libraries (or “packages”) for data wrangling purposes.
Packages are collections of pre-written modules that can automate processes a data analyst would otherwise have to complete manually. For example, when standardizing the country name format for a set of data, a data analyst would have to manually sift through the data to categorize it correctly.
A library created for this purpose, however, would contain existing wrangling algorithms with datasets for dealing with common transformations of data. One example of this would be to create an algorithm that would transform the word “Germany” in every language into the text string “Germany.”
What Is the Data Wrangling Process?

Data wrangling is a linear process that follows these steps:
Discovery
The first step in wrangling data is establishing what information you want to gain from it and how you intend to use it. Depending on these conditions, the way data analysts will need to structure and format the data will change.
Structuring
Once a clear goal has been set out, data analysts will take the first steps to transform the raw data into something manageable. This will include standardizing the main entries so the data can be properly organized—for example, standardizing country names and date formats.
Cleaning
The process of cleaning data involves removing anything that would impede the data mining process later on. Errors, null entries, duplicate entries, and datasets that are not in the correct place will all be removed.
Enriching
At this stage, data analysts will determine whether adding additional data would benefit their analysis. For instance, when analyzing data on European countries, it might help to know whether a country is a member of the European Union or not. Adding this information as a new column in the database will allow analysts to query based on those conditions when data mining, rather than having to list all the EU countries manually.
Validating
Data is heavily manipulated during the wrangling process, so the validation step checks the quality of the outcome. Has any core data been accidentally changed? Has the standardization been fully applied so nothing is returned when you query for a format that you intended to remove? Have any errors gone unnoticed? Even small errors will affect the final outcomes of the analysis, so the quality check needs to be extensive and thorough.
Publishing
When the data has reached an acceptable state, meaning that it’s standardized, without errors, sorted, categorized, and primed to be mined for useful information, analysis can begin.
Data analysts will mine and analyze the cleaned-up data according to the original purposes and goals outlined during the initial “discovery” step and will publish their results to be used by their clients.
Other Data Management Processes
Below is a useful list of other data management processes and how they differ from data wrangling. All of these processes are studied in both data analytics and data science bootcamps, so they will be useful no matter which field you’re interested in. Of course, the two fields do have some similarities, so if you’re unsure, check out whether a data analytics or data science career is right for you.
Data Wrangling vs. Data Mining
Data mining is extracting useful patterns and information from data that has already been wrangled. The data is queried and studied so that you can properly understand the information it is giving to you. The correct conclusions can’t always be discerned by simply looking at the numbers.
Data Wrangling vs. Data Cleaning
Data cleaning is the process of removing unwanted entries from your chunk of data. This includes duplicate entries, errors, and null (invalid) entries.
Data Wrangling vs. Data Munging
Data munging is another term for data wrangling, meaning the munging process refers to restructuring and cleaning complex data sets.
Data Wrangling vs. Data Analysis
Analytics processes are the final step after wrangling and mining the data. This is where the information and patterns that have been discerned from the (now clean and queryable) data are studied to determine how they affect and relate to the original objectives of the business users.
You can also conduct data analysis using Python, or analyze the data through machine learning.
When Should You Use Data Wrangling?
Data wrangling is used when you get data from different sources and need to make changes to it before being able to put it into a database and run queries. Here are some examples of when this would be necessary.
- Digitizing records. Different people will write dates and addresses and other information in different ways, so once digitized, the data will need to be standardized.
- Optical Character Recognition (OCR). This automated process is used when manually transferring data from paper would be too expensive. OCR can digitize the data automatically, but it will not be without mistakes that need to be wrangled.
- Collecting data from different countries. Different countries use different formats for data entry. For example, Denmark separates numbers with a period instead of a comma (35.000 = thirty-five thousand). Data from different sources like this needs to be standardized so it can all be queried together in one big database.
- Scraping information from websites. Information on websites is stored and presented in a format readable and comprehensible for humans, not databases. When scraping websites for data, it will need to be wrangled into a format suitable for databases and querying.
Data Wrangling Examples
In this section, we’ll show you a few quick examples of data wrangling in action.
- Structuring: standardizing a name format using Pandas
Let’s use the same data from the earlier screenshots and wrangle the country names to get rid of “Deutschland.” We will use Python and the well-known Pandas package to simplify this.

Here is our sample data in Python and converted into a pandas DataFrame. This is the output:
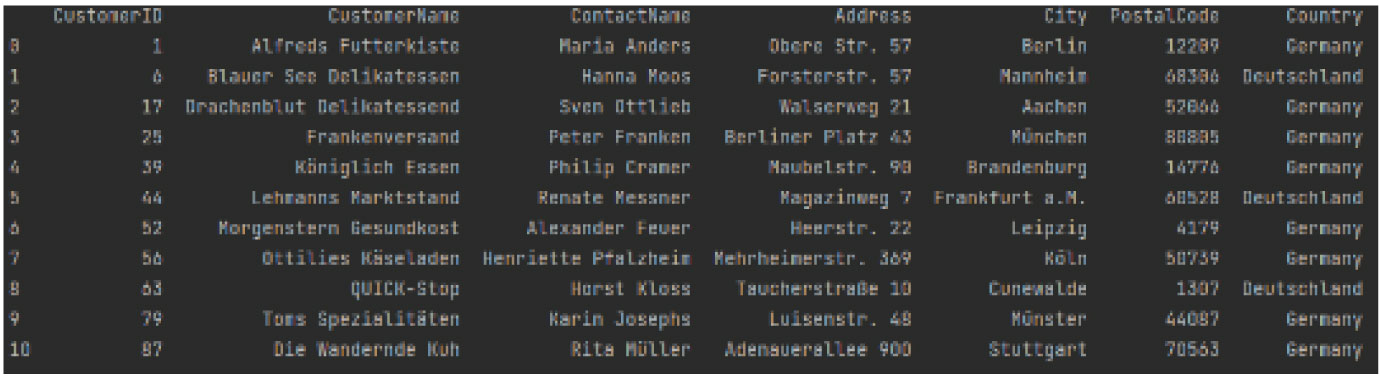
As you can see, Deutschland is present in a few of the data entries. Time to fix that!
Pandas makes this remarkably simple. You can just add a line before you print it out, remapping “Deutschland” to “Germany.”


- Cleaning: removing duplicates from a data set using Pandas
Let’s look at a smaller set of data that has a problem with duplication.

Data Wrangling FAQs
Below, we’ll answer two of the most common questions regarding data wrangling.
Is Data Wrangling Worth It?
Yes. In many cases, you can’t use data if you don’t wrangle it first. If you mine and analyze un-wrangled data, the information could be anywhere from slightly to absurdly incorrect. Essentially, any parts of the data that weren’t formatted appropriately would not have been used correctly in the analysis and would throw off all results.
When Shouldn’t You Use Data Wrangling?
Data wrangling is used to manipulate data so it can be utilized by business users. To know whether you need to wrangle your data, you need to figure out what it is you want to do with it, and whether it is possible in the data’s current state. If that’s the case, then you don’t need to wrangle the data.
Since you’re here…
Curious about a career in data science? Experiment with our free data science learning path, or join our Data Science Bootcamp, where you’ll get your tuition back if you don’t land a job after graduating. We’re confident because our courses work – check out our student success stories to get inspired.


