
In this blog post, we are going to discuss the ‘K Means clustering Machine Learning algorithm’. Unlike the KNN Algorithm, K Means clustering is an Unsupervised Learning algorithm. Unsupervised learning does not involve the target output which means no training is provided to the system. And the system must learn on its own through determining and adapting to the structural characteristics in the input patterns. Unsupervised learning method works with unlabeled data in which the output is just based on the result of observations. Unsupervised learning generates a moderate accurate output but it is reliable. We can see below the different types of Unsupervised learning algorithms.
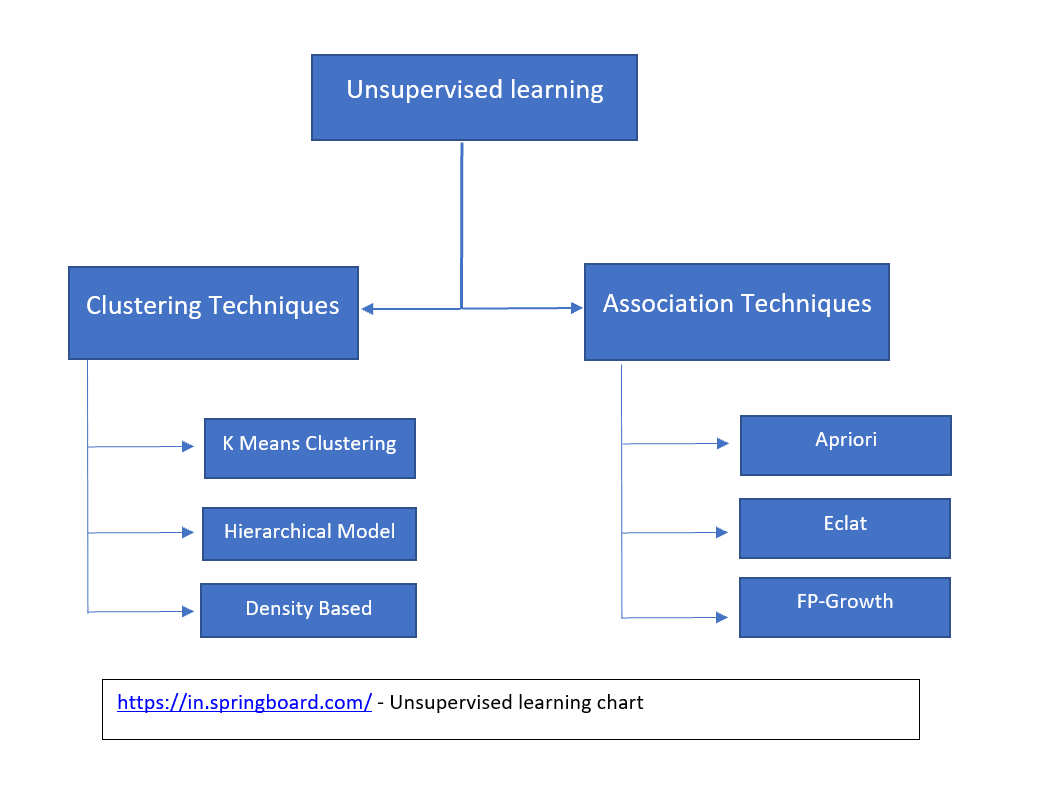
Now we will look at the Clustering technique and its use cases.
Inspired by this analysis and want to learn how to do it / wish to replicate this for your project? We can help you there. Just leave your email address in this google form and we will share the analysis with you within 48 hours.
K Means Clustering: Clustering Technique
Clustering is an unsupervised learning technique. Gestalt’s Law of similarity says that if two things are similar in some ways, they often share other characteristics. Similarly, a cluster is a set of similar data points or a set of points that are more similar to each other than to points in other clusters. In clustering unsupervised learning techniques, we provide unlabeled training datasets to an algorithm and we ask the algorithm to find some structure in the data. Output can be in the form of clustered or density-based or hierarchical.
Clustering techniques can be used for:
1) Market Segmentation: Analyzing market and customer requirements to target the sale of selective products in certain demography.
2) Social Network Analysis: Based on user habits and social interactions we can group users in a certain cluster, assisting effective communication.
3) Detecting Anomalies or Outliers: Using clustering techniques to identify the outliers student in the classroom as some students outperformed other students or failed to even pass. Another example of anomaly detection would be Fraud detection in credit card transactions in banks.
In this post, we will discuss only the K Means Clustering Algorithm, its implementation, and use cases.
Get To Know Other Data Science Students

Jonathan King
Sr. Healthcare Analyst at IBM

Karen Masterson
Data Analyst at Verizon Digital Media Services

Isabel Van Zijl
Lead Data Analyst at Kinship
K Means Clustering Algorithm
K Means Clustering Algorithm is the most popular algorithm. K-Means is an iterative algorithm. Let’s imagine we have a set of unlabeled data and we want to group the dataset into three clusters. K-Means the algorithm will assign each data point to one of the K groups based on the feature and similarities. Here are the steps by which we can achieve this using K-Means clustering:
- We will define the value of K which means we are going to create a K number of clusters. As in our example, we would like to create 3 cluster groups from the data set. so, the value of K will be 3.
- Initialize two randomly selected points from the cluster. This is called a centroid.
- Traverse dataset till the last data point and assign then to cluster/group.
Implementation of K Means Clustering Algorithm
For our implementation, we are using Juypter Notebook and executing our algorithm in python v3.0.We have also created one sample dataset on which we will implement the K-Means algorithm. Below are the columns and few rows from our dataset:
| CustomerId | CreditScore | Purchase In Lacs | State |
| 91001 | 68 | 5 | Active |
| 91002 | 84 | 8 | Active |
| 91003 | 59 | 21 | Active |
| 91004 | 85 | 4 | Active |
| 91005 | 91 | 3 | Active |
- Let us start by loading the necessary libraries. We are using NumPy for scientific computing with python. It’s a widely opensource library used for applying data science. Also, we are loading Mathplotlib for multiplatform data visualization. To implement K-Means clustering, we are going to load sklearn.cluster(https://scikit-learn.org/stable/modules/clustering.html) module.

Related Read: Data Scientist Job Description
2) Now we will load our dataset which has these columns – CustomerId, CreditScore, Purchase Amount, State.

3) Next, we will select only two columns from the dataset on which we want to perform the K-Means algorithm. We are using iloc function from pandas to select the required columns and assign that to the X vector.

4) Let us specify how many cluster groups we would like to create. In this example, we are going to work with 3 clusters.

5) Now create Y cluster for predicting the X vector. Here we are going to use fit. predict method and this is how it will look. Now Y_kmeans contain predicted value by K-mean:

6) Let us visualize the cluster using the plt.scatter method. Here we are going to create 3 scatters one for each cluster and label them as Cluster 1, Cluster 2 and Cluster 3.

7) We have added labels for X and Y vectors as CreditScore and Purchase amount. The output plot graph will look like this.

The outputs of performing K Means clustering algorithm on a dataset are:
1) K centroids: Centroids for each of the k clusters identified from the dataset.
2) Complete dataset labeled to ensure each data point is assigned to one of the clusters.
Inspired by this analysis and want to learn how to do it / wish to replicate this for your project? We can help you there. Just leave your email address in this google form and we will share the analysis with you within 48 hours.
Use Cases of K-Means Algorithm
1) Document Clustering: Classification of documents based on topics or content of the document.
2) IT Alert based Clustering: By clustering of operational alerts, we can identify the categories of alerts could be network related, Database related or application related alerts or mean-time to repair the alert or system failure predictions.
3) Fraud detection: Identifying the fraud from the historical dataset and cluster them into one group.
4) Market Segment: Clustering of customer database and grouping them to different market segments.
K Means clustering is one of the widely used clustering algorithms and very popular amongst data experts. Other algorithms in the clustering technique are the Density-based Clustering and Hierarchical model. We will discuss these algorithms in the coming posts.
Since you’re here…
Curious about a career in data science? Experiment with our free data science learning path, or join our Data Science Bootcamp, where you’ll get your tuition back if you don’t land a job after graduating. We’re confident because our courses work – check out our student success stories to get inspired.


