
While theoretical machine learning knowledge is important, hiring managers value production engineering skills above all when looking to fill a machine learning role. To become job-ready, aspiring machine learning engineers must build applied skills through project-based learning. Machine learning projects can help reinforce different technical concepts and can be used to showcase a dynamic skill set as part of your professional portfolio.
No matter your skill level, you’ll be able to find machine learning project ideas that excite and challenge you. For inspiration, we’ve gathered examples of real-world ML projects geared towards beginner, intermediate, and advanced skill levels. Using these projects as templates, we’ll explore what a completed project should look like and discuss actionable tips for building your own impressive machine learning project.
Machine Learning Projects
First, we’ll examine basic machine learning projects geared toward learners who are proficient with R or Python (the most renowned language in the field of data science and machine learning) programming language and want to experiment with machine learning fundamentals. Next, we’ll review ML project ideas suited for those with intermediate and advanced machine learning skills.
Machine Learning Project Ideas for Beginners
Titanic Survival Project
After striking an iceberg, the so-called “unsinkable” RMS Titanic disappeared into the icy waters of the North Atlantic on April 15th, 1912. Over half of the ship’s 2224 passengers and crew members perished, and demographic data shows that some people aboard were more likely to survive than others.
This Kaggle project asks participants to build a model that predicts passenger survival based on passenger information like ticket class, gender, age, port of embarkation, and more. Kaggle offers a training data set that participants can use to build their own machine learning models, which can be constructed locally or on Kaggle Kernels (a no-setup, customizable Jupyter Notebooks environment with free GPUs).
Identifying Twits on Twitter Using Natural Language Processing

Try your hand at determining the probability that a given tweet originated from a particular user with sentiment analysis. This natural language processing technique can scan thousands of text documents for specific filters in a matter of seconds. This technique is how Twitter, for example, can scan and separate out tweets that contain racist or misogynistic content.
For inspiration, check out Eugene Aiken’s application of natural language processing to determine the probability that certain tweets were published by either Donald Trump or Hillary Clinton. To conduct a similar project, you’ll need to pick two users, scrape their tweets, run your twitter data through a natural language processor, classify it with a machine learning algorithm, and use the predict-proba method to determine probabilities. Learn more about the original project here and download the data set here.
Housing Prices Prediction
This Kaggle competition will help you practice creative feature engineering as well as regression techniques like random forest and gradient boosting. The goal of the project is to predict the final sales price of a home based on the Ames Housing Dataset.
The data includes 79 explanatory variables that describe vital attributes of homes in the city of Ames, Iowa. These data points range from zoning classification to lot size, remodel date, proximity to a railroad, and even masonry veneer type. The effect of each characteristic on house prices might surprise you!
Google Search Analysis With Python
Google users perform roughly 3.5 billion search engine queries per day. If you’re wondering what people are Googling, try using Google Trends to analyze a keyword of your choice. Google Trends offers an API called pytrends, which Aman Kharwal used to analyze the performance of the keyword, “machine learning.”
Aman used this tool to pinpoint 10 countries with the highest number of searches for “machine learning,” and also determined how the number of “machine learning” search queries changed over time. After conducting his analysis, Aman then used data visualizations to communicate his findings. Try building your own data visualization and consider what story your results might tell, and how that information could be important in a business context.
Chatbot Using Python
Chatbots are AI-powered applications that simulate human conversation, and are often implemented to field simple customer queries online. If you’re interested in natural language processing, try creating a Chatbot with Python’s NTLK library.
First, you’ll need to compile a list of queries and their correlating responses for the chatbot. Next, you’ll run the program and try out your queries with the chatbot. Once you’re satisfied with your baseline chatbot, you can use additional Python NLP packages or add more queries. To get started, take a look at Aman Khalwar’s guide to creating a chatbot with Python.
Image Recognition
If you’re curious about computer vision, check out this Kaggle competition, which invites participants to build a digit recognizer using the classic MNIST dataset of handwritten numbers. The MNIST dataset—commonly referred to as the “Hello World” of machine learnings—comes equipped with pre-extracted features, which will streamline your data processing. Overall, this competition is an excellent introduction to simple neural networks, computer vision fundamentals, and classification methods like SVMs (Support Vector Machines) and K-nearest neighbors.
The competition also includes links to Python tutorials, as well as information about the details of the dataset (including previously applied algorithms and their levels of success).
Python Recommendation Engine
Building a recommendation engine sounds like a difficult task for a beginner, but your code can be as simple or as complex as you’d like. To create a basic content-based recommendation system, you’ll just need to maintain a log of items a user has seen and liked and calculate the top-N most similar products that user has not yet seen. A simple collaborative filtering recommendation engine can be powered by a user-user similarity matrix that recommends items that similar users like.
To learn more about building a Python recommendation engine, check out this Kaggle notebook, which explains how to implement collaborative filtering and content-based filtering in Python to generate personalized recommendations. The notebook explores these concepts using a rich, rare dataset about article sharing.
Intermediate Machine Learning Projects

Finding Frauds While Tracking Imbalanced Data
From banking via smartphones to AI-fueled stock price prediction, the financial sector embraces a cloud-based future. Thanks to a rising financial crime rate, the importance of AI-powered fraud detection is greater than ever. But because fraudulent financial interactions comprise only a small portion of the total number of financial transactions that occur daily, analysts must figure out how to reliably detect fraud with imbalanced data.
Fraud detection is a classification problem that deals with imbalanced data, meaning the issue to be predicted (fraud) is in the minority. As such, predictive models often struggle to generate real business value from imbalanced data, and sometimes results may be incorrect.
To address the issue, you can implement three different strategies:
- Oversampling
- Undersampling
- A combined approach
A combination approach can strike a balance between precision and recall, but you may choose to prioritize one over the other depending on the demands of your project and your desired business outcomes. You can learn more about conducting fraud detection with imbalanced data here.
Market Basket Analysis
With this Kaggle dataset, you can deploy an apriori algorithm to analyze and predict customer purchasing behaviors, otherwise known as Market Basket Analysis. Retailers often use this modeling technique used by retailers to determine associations between items based on rules of conditional probability.
As per the theory of Market Basket Analysis, if a customer buys a certain group of items, that customer is likely to buy related items as well. For example, purchasing baby formula often carries a correlation with buying diapers. This particular Kaggle dataset contains information about customers’ grocery purchases.
Text Summary
Text summarization condenses a piece of text while preserving its meaning. Increasingly, text summarization is being automated with Natural Language Processing. Extractive text summarization uses a scoring function to identify and lift key pieces of text from a document and assemble them into an edited version of the original. Abstractive text summarization, however, uses advanced natural language processing techniques to generate a new, shorter version that conveys the same information.
To create a text summarization system with machine learning, you’ll need familiarity with Pandas, Numpy, and NTLK. You’ll also need to use unsupervised learning algorithms like the Glove method (developed by Stanford) for word representation. Find a step-by-step guide to text summarization system building here.
Get To Know Other Data Science Students

Bret Marshall
Software Engineer at Growers Edge

Nick Lenczewski
Data Scientist at Ovative Group

Bryan Dickinson
Senior Marketing Analyst at REI
Black Friday Sales Prediction
Want to work on a regression model and expand your feature engineering skills? With this practice problem from Analytics Vidhya, you can use retail sales data to make predictions about Black Friday sales.
The dataset contains demographic information for customers (including age, gender, marital status, location, and more) as well as product details and total purchase amounts. A training data set and a testing data set are available.
Text Mining
From emails to social media posts, 80% of extant text data is unstructured. Text mining is a way to extract valuable insights from this type of raw data. The process of text mining transforms unstructured text data into a structured format, facilitating the identification of key patterns and relationships within data sets.
To try your hand at text mining, experiment with these publicly available text data sets, which are geared towards multi-level classification, which is an important aspect of natural language processing. The Extreme Classification Repository that contains these data sets also provides resources that can be used to evaluate the performance of multi-label algorithms.
Million Song Analysis
Use this subset of the Million Song Dataset to predict the release year of a song from its audio features. The songs are primarily commercial Western tracks dating from 1922 to 2011, although the dataset does not include any audio—it consists of derived features only.
The core of the dataset is feature analysis and metadata related to each track. Song descriptions include values expressing danceability, loudness, duration of the track in seconds, and much more.
Movie Recommendation Engine

Netflix uses collaborative filtering as part of its complex recommendation system, and with the MovieLens Dataset, you can too! Collaborative filtering recommendation engines analyze user behavior/preferences and similarities between users to predict what users will like.
For example, if User A rated Spiderman, Batman Returns, and X-Men highly and User B gave high ratings to Batman Returns, X-Men, and Wonder Woman, a collaborative filtering algorithm would identify that both users enjoy superhero movies. Based on their shared behaviors, the system would recommend Wonder Woman to User A and Spiderman to User B.
The MovieLens 1M Data Set contains 1,000,209 ratings of roughly 3,9000 movies from 6,040 MovieLens users who joined MovieLens in 2000. The data set notes the genre of each film as well as the gender, occupation, age, and zip code of each user. You can learn more about building a movie recommendation engine with this data set here.
Advanced Machine Learning Projects
Catching Crooks on the Hook Using Geo-Mapping and Cloud Computing
Global Fishing Watch is a website launched by Google in partnership with environmental nonprofits to monitor commercial fishing activities worldwide, with the goal of reducing overfishing, illegal fishing, and marine habitat destruction.
Global Fishing Watch identifies and tracks illegal fishing activity by harvesting GPS data from ships and processing GPS data and other important information with neural networks. 60 million data points from 300,000+ vessels are harvested daily, and the website’s algorithm has learned to classify these ships by type (sail, cargo, or fishing), fishing gear (grawl, longline, purse seine), and fishing behaviors (where and when a vessel is active).
Global Fishing Watch shares vessel tracking information publicly, meaning anyone can download the website’s data and even track commercial fishing activity in real time. To warm up, see if you can use supervised classification to determine whether a vessel is fishing.
Download Global Fishing Watch datasets and find links to GitHub documentation and details here.
Uber Helpful Customer Support Using Deep Learning
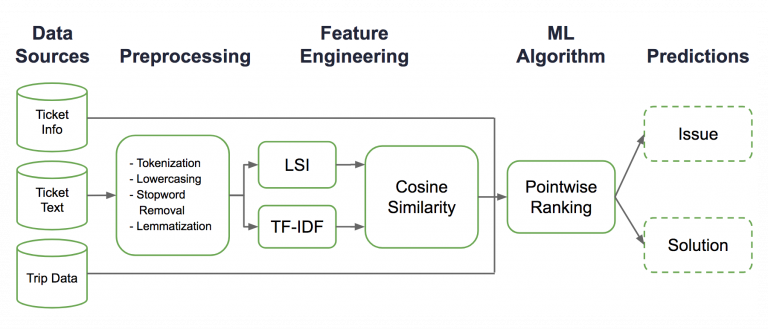
To resolve customer issues with efficiency and ease, Uber developed a machine learning tool called COTA (Customer Obsession Ticket Assistant) to process customer support tickets using “human-in-the-loop” model architecture. Essentially, COTA uses machine learning and natural language processing techniques to rank tickets, identify ticket issues, and suggest solutions.
This project is great inspiration for anyone interested in applied machine learning and actual implementation. Uber also used A/B testing to evaluate two versions of their COTA model to assess impacts on ticket handling time, customer satisfaction, and revenue. Consider learning more about COTA if you’re interested in deep learning projects that combine clever technical architecture with human input.
Barbie With Brains Using Deep Learning Algorithms
Talking dolls that regurgitate pre-recorded phrases are nothing new—but what if dolls could actually listen and respond to kids? Enter Hello Barbie.
To create Hello Barbie, Mattel used natural language processing and advanced audio analytics that enabled the doll to interact logically in conversation. With the push of a button cleverly integrated into her outfit, Hello Barbie was able to record conversations and upload them to servers operated by ToyTalk, where the data was analyzed.
While some were excited that the doll could learn about users over time, Hello Barbie was met with public backlash around privacy concerns and eventually was discontinued. While this application of natural language processing proved contentious, those interested in complex deep learning architectures might find inspiration in the mechanics of the project.
Netflix Artwork Personalization Using Artificial Intelligence
Netflix marshalls sophisticated AI solutions to personalize title recommendations for users. But personalization at Netflix doesn’t stop there—the streaming behemoth also personalizes the artwork and imagery used to convey those titles to users.
The goal is to show you what you like, so if you’ve watched several movies starring Uma Thurman, you’d be likely to see Pulp Fiction art featuring her instead of co-stars John Travolta or Samuel L. Jackson.
To do so, Netflix uses a convolutional neural network that analyzes visual imagery. The company explains that they also rely on “contextual bandits,” which continually work to determine which artwork gets better engagement. Find out more about how to harness machine learning for artwork personalization here.
Myers-Briggs Personality Prediction
The Myers Briggs Type Indicator is a popular personality test that divides people into 16 different personality types across 4 axes. With this Kaggle dataset, you can evaluate the efficacy of the test and attempt to identify patterns related to personality type and writing style Each row in this dataset contains a person’s Myers-Briggs personality type along with examples of their writing.
The dataset could potentially be used to evaluate the validity of the Myers-Briggs test as it relates to the analysis, prediction, or categorization of human behavior. For example, you could apply machine learning techniques to examine the test’s ability to predict linguistic style and online behavior. Alternatively, try creating an algorithm that determines a subject’s personality type based on their writing.
YouTube Comment Analysis
If you want to analyze YouTube comments with natural language processing techniques, start by scraping your text data by leveraging a library like Youtube-Comment-Scraper-Python, which fetches YouTube video comments using browser automation.
With automated scraping, you’ll be able to focus your energy on exploratory data analysis, feature engineering, and other more advanced steps in the standard natural language processing workflow. Consider using your data to explore sentiment analysis, topic modeling, or word clouds.
Hate Speech Detection

Are you concerned about the growing prevalence of hate speech online? Try training a hate speech detection model using Python.
The United States does not have laws that prohibit hate speech, as the U.S. Supreme Court has ruled that criminalizing hate speech violates the constitutional right to free speech. However, the United Nations defines gate speech as communications that attack or use discriminatory language related to a person’s religion, ethnicity, race, gender, and other identity markers.
Using this definition of hate speech, you can develop a hate speech detection model using a dataset originally collected from Twitter. This interesting machine learning problem will revolve around sentiment classification. Learn more about creating a hate speech detection model with Python here.
Tips To Generate Your Own Machine Learning Project Ideas
If you need to jumpstart your project ideation, here are a few tips to put you on the right track.
Pick an Idea That Excites You

Create high-level concepts around your interests. If you’re passionate about fair housing, for example, learn more about how housing authorities in California are using AI to analyze and plan affordable housing strategies. Then consider building your own model using HUD or U.S. Census datasets.
If you’re a movie buff and aspire to work in the streaming space, peruse the Netflix Tech Blog for inspiration and try building different types of recommendation systems powered by collaborative filtering, content filtering, or a hybrid model.
Whatever topic you choose, solidify your most viable idea with a written proposal, which will serve as a blueprint to refer back to throughout the project.
Avoid Going Out of Scope
Scoping is the first stage of machine learning project planning, and offers an opportunity to settle on a data question, identify your objective, and select the machine learning solutions you will harness to solve your problem.
If you’re new to machine learning, focus on simple projects. Pick a small, succinctly-defined problem and research a lage, relevant data set to increase the odds that your project will generate a positive return on investment.
Test Your Hypothesis
In a machine learning context, hypothesis testing is conducted to confirm initial observations catalogued during data exploration and validate these assumptions for a desired significance level. First, you’ll model your hypothesis, and then you’ll select your hypothesis test type based on your predictor variable type (quantitative or categorical). Python is the easiest language for beginners who want to conduct hypothesis testing.
Implement the Results
Once you’ve reached all the desired outcomes, you’ll be ready to implement your project. This stage consists of several steps:
- Creating an API (application programming interface). This allows you to integrate your machine learning insights into the product.
- Record results on a single database. Collating your results will allow you to build upon them more easily.
- Embed the code. If you’re short on time, embedding the code is faster than an API.
Revise and Learn
When you’ve finished the project, evaluate your findings. Think about what happened, and why. What could you have done differently? As you gain experience, you will be able to learn from your mistakes over time.
ML Project Tips

Both simple and complex machine learning projects should be well-organized, properly documented, and presented in an impactful way. No matter your level of expertise, here are some concrete steps you can take to make your project shine.
How To Organize a Machine Learning Project
Properly organizing your machine learning project will boost productivity, ensure reproducibility, and make your project more accessible to other machine learning engineers and data scientists. When organizing your project, be sure to:
- Streamline your file structure. In your main project folder, create subfolders for notes, input files and data, src, models, and notebooks. If you’re working on GitHub, don’t forget to create a README.md file to introduce newcomers to your project.
- Manage data effectively. Use a directory structure and do not directly modify raw data. Be sure to check the consistency of your data and use a GNU make.
- Keep your code clean. Be sure to provide thorough documentation and organize your code into functional, annotated units.
How To Start a Machine Learning Project
Ready to get started on your project? Here’s how to begin:
- Identify your problem. What problem are you looking to solve, and why? Figure out which AI solution you will use to address the problem.
- Acquire your data. Download open-source data or try your hand at web scraping.
- Prepare your data. You may need to clean your data to eliminate unnecessary data or features. You may also need to transform your data, particularly if it is unstructured. Finally, you may also choose to conduct exploratory data analysis to look for patterns that might inform your project.
Once your data is prepared, you’ll be ready to develop your machine learning model.
How To Measure, Review, and Document an ML Project
To evaluate your machine learning project, you’ll need to use metrics to measure the performance of your model. The metrics you use will depend on your problem type. The performance of a classification model can be measured using metrics like accuracy, precision, and more. Specific evaluation metrics exist for regression, natural language processing, computer vision, deep learning, and other types of problems.
Before signing off on your project, you’ll need to review your work for quality assurance and reproducibility. To review your project, explain how you framed your question as a machine learning task and how you prepared your data. You should also compare your training, validation, and test metrics, and explain how you validated your model. Finally, you should note potential improvements and consider how you would deploy your model.
To share your work with others, you’ll also need to document your machine learning project. Your documentation should offer the information necessary to reproduce your work. It should clearly and succinctly outline the problem attacked, your proposed machine learning solution, and evidence of the solution’s success. Your project documentation should include:
- An executive summary of the project
- Context and background information about the problem
- A list of data sources
- Model documentation
- Validation performance results
- Appendix with source code
Once you’ve evaluated, reviewed, and documented your project, you’ll be able to show it to hiring managers.
How To Include a Machine Learning Project on Your Resume

Your machine learning resume should highlight what you can do for your employer. When adding a project to your resume, use it to demonstrate how you would create business value in your new role. cf
Frame your contributions to a project as accomplishments while using numbers and key metrics to convey your successes. Be sure to include the project title and a link to the project itself. After briefly describing the project, note the tools, programs, and skills used—and emphasize any that overlap with those detailed in the description of your desired role.
Since you’re here…
Curious about a career in data science? Experiment with our free data science learning path, or join our Data Science Bootcamp, where you’ll get your tuition back if you don’t land a job after graduating. We’re confident because our courses work – check out our student success stories to get inspired.


