Basically, text data is data that consists of natural language. In other words, writing. The internet is covered in it. The issue is that computers don’t have a way of parsing natural language as intuitively as human beings do. Interpreting what a sentence means—that becomes a really hard math problem.
Formal languages like algebra are easy for the computer to interpret, but natural language is not a format that is native for quantitative analysis. It’s a distinction that’s made when thinking about language in the context of a computer. All of the statistical methods and machine learning methods that we have—for the most part, what they really, really like are matrices of numbers. So there’s this problem of turning natural language into matrices of numbers and doing that in a way that’s appropriate to the problem.
For my first capstone project, I had this data set that was all complaints that people made about their banks to the Consumer Financial Protection Bureau. The CFPB makes this data public, so I grabbed it.
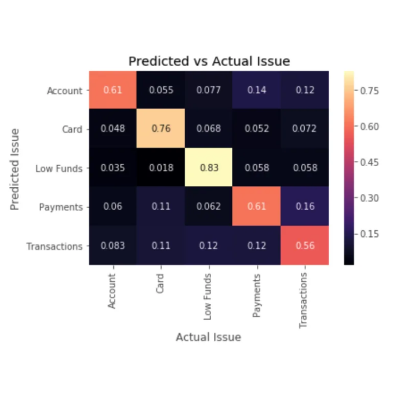
(This plot describes the model performance with a confusion matrix.)
These emails belonged in categories and had been labeled by humans. So, imagine these emails are coming in bins to different customer service agents who specialize in different areas. To solve the problem of routing them, you might want a program that can take the text of the email, put it in the appropriate bin, and send that to the right agent.
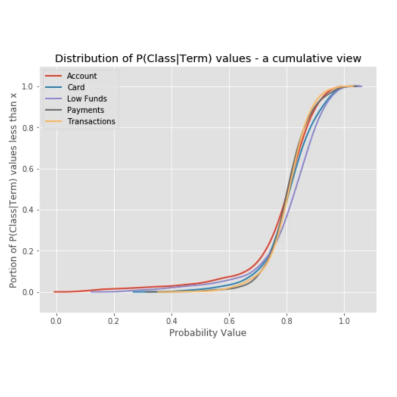
This plot shows the distribution of how strongly terms tended to be associated with a particular class. More technically, the probability that a document belongs to a class given that the term occurred in that document.

 Some of the terms that were used as features for the classifier.
Some of the terms that were used as features for the classifier.




