“Machine learning” is one of the current technology buzzwords, often used in parallel with artificial intelligence, deep learning, and big data, but what does it actually mean? And what other machine learning terminology is important to understand?
McKinsey has defined machine learning as “algorithms that can learn from data without relying on rules-based programming.” Carnegie Mellon University offers this: “The field of Machine Learning seeks to answer the question ‘How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?’”
Machine learning means that the accuracy of the system is improving over time, with the addition of more data and feedback. You probably encounter many examples of machine learning every day without realizing it. When Facebook suggests “people you might know” or when Amazon emails you recommendations of products you might like based on previous purchases, they are using machine learning algorithms to customize your results.
Machine learning deepens the work of artificial intelligence. In AI, researchers originally created rules for computers to make decisions. With machine learning, computers actually “learn” for themselves and design new rules through practice and repetition.
(Source.)
From medical diagnoses to fraud detection, machine learning is improving our capability to solve societal problems. Paypal acquired the ML startup Simility to analyze millions of transactions and flag anomalies to prevent money laundering. Machine learning can also predict hypoxaemia (low oxygen levels) during surgery; recognize cardiovascular risk factors like high blood pressure, age, and smoking in retinal images; and identify abnormal growths during colonoscopies.
Adopting machine learning at scale is not without challenges. Machine learning can lead to overfitting (when the machine predicts outcomes based on historical data, but does not adapt to new variables) and sometimes it is difficult to find large enough data samples for the machines to train with.
Although many people worry about ML replacing humans, people and machines complement each other in many ways. According to the Harvard Business Review, “through… collaborative intelligence, humans and AI actively enhance each other’s complementary strengths: the leadership, teamwork, creativity, and social skills of the former, and the speed, scalability, and quantitative capabilities of the latter.”
Humans can help train and operate machines and explain their behavior. When Microsoft developed the ML bot Cortana, it required substantial data points and human insights to create a personality that was “confident, caring, and helpful but not bossy.” A poet, a novelist, and a playwright were all part of the team that trained the bot on how to communicate effectively with humans.
Machine learning is full of interesting variants and subfields, so let’s start decoding other machine learning terminology.

Machine Learning Terminology
Classification
Classification is a part of supervised learning (learning with labeled data) through which data inputs can be easily separated into categories. In machine learning, there can be binary classifiers with only two outcomes (e.g., spam, non-spam) or multi-class classifiers (e.g., types of books, animal species, etc.).
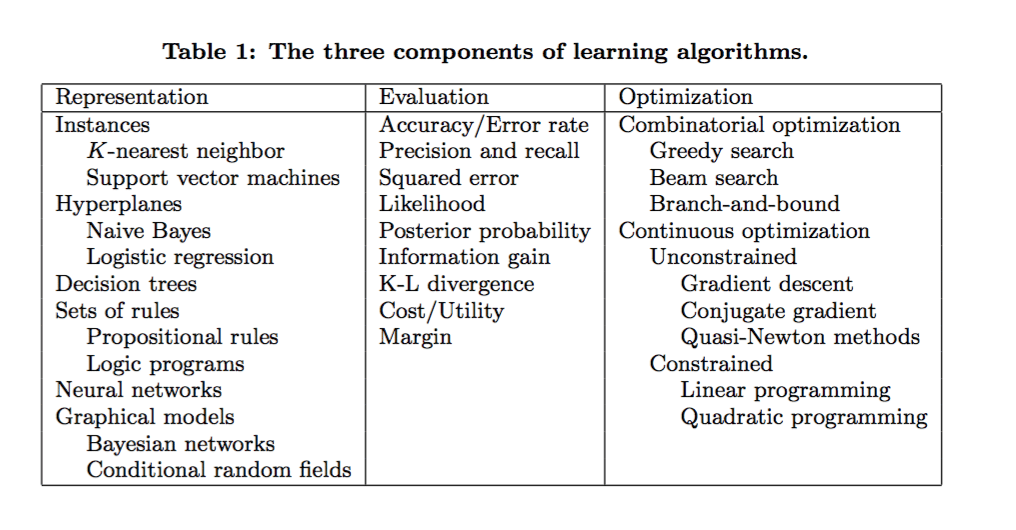
One of the most popular classification algorithms is a decision tree (essential for both data scientists and machine learning engineers), whereby repeated questions leading to precise classifications can build an “if-then” framework for narrowing down the pool of possibilities over time.
You can learn about other classification algorithms, like naive Bayes, k-nearest neighbor, and artificial neural networks, here.
(Source.)
Clustering
Clustering is a form of unsupervised learning (learning with unlabeled data) that involves grouping data points according to features and attributes.
Clustering can be used to organize customer demographics and purchasing behavior into specific segments for targeting and product positioning. It can also analyze housing quality and geographic locations to create real estate valuations and plan the layout of new city developments. It can classify information by topics within libraries or web pages and compile an easily accessible directory for users.
The most common kind of clustering is K-means clustering, which involves representing each cluster by a variable “k” and then defining the centroid of those clusters. All data points are then assigned to a particular cluster and, through this process, we identify the centroid of the new clusters. Here are a few examples of what K-means clustering looks like in practice:
- A hospital wants to locate emergency units at the minimum possible distance from areas where accidents frequently happen
- A seismologist studies regions where earthquakes have occurred over the last few decades to identify the areas of greatest risk
- A pizzeria wants to understand where to locate stores based on customer demand to minimize the distance the drivers need to travel for delivery
Other clustering methods that you can learn more about here include density-based clustering, hierarchical-based methods, partitioning methods, and grid-based methods.
Regressions
Regressions create relationships and correlations between different types of data. For example, each profile picture has an image with pixels that belong to a person. With static prediction (one that stays the same over time), machine learning acknowledges that a certain pixel arrangement corresponds to a given name and allows for facial recognition (for example, when Facebook recommends tags for the photos you’ve just uploaded).
Regressions can also be useful when predicting outcomes based on data in the present. For a long time, statistical regression has been used to solve problems, such as predicting the recovery of cognitive functions after a stroke or predicting customer churn in the telecommunications industry. The only difference is that now many of these regression analyses can be done more efficiently and quickly by machines.
Regression is a type of structured machine learning algorithm where we can label the inputs and outputs. Linear regression provides outputs with continuous variables (any value within a range), such as pricing data. Logistical regression is when variables are categorically dependent and the labeled variables are precisely defined. For example, you can classify whether a store is open as (1) or (0), but there are only two possibilities.
Other types of regression that you can explore here are polynomial regression, support vector regression, decision tree regression, and random forest regression.
Get To Know Other Data Science Students

Jasmine Kyung
Senior Operations Engineer at Raytheon Technologies

Aaron Pujanandez
Dir. Of Data Science And Analytics at Deep Labs

Leoman Momoh
Senior Data Engineer at Enterprise Products
Deep Learning
Deep learning is similar to machine learning—in fact, it’s more of an application of machine learning that imitates the workings of the human brain. Deep learning networks interpret big data (data that is too large to fit on a single computer)—both unstructured and structured—and recognize patterns. The more data they can “learn” from, the more informed and accurate their decisions will be. Here are some examples of deep learning in practice:
- Chatbots and virtual assistants: Virtual assistants like Alexa and Siri or customer service chatbots on different web pages can receive human requests, decipher language, and present lifelike responses.
- Real-time bidding and programmatic advertising: Advertising now depends on software buying advertising space through a competitive bidding process. Cognitiv AI is an example of a deep learning platform that synthesizes data on customer demographics, weather, available inventory, time of day, and other variables to create custom buying algorithms for a specific target market.
- Recommendation engines: From travel sites like Booking.com and Expedia to streaming platforms like Netflix and Spotify, recommendation engines learn from past purchasing or usage behavior to customize marketing. There are two forms of recommendation engines: collaborative, where user preference data is collected at scale and users are compared to similar user personas, and content-based filtering, where properties of specific items are analyzed and future items are compared to past items to determine the closest matches.
Neural Networks
Neural networks are closely related to deep learning. They create sequential layers of neurons that deepen the understanding of data collected from a machine to provide an accurate analysis.
Related: A Beginner’s Guide to Neural Networks in Python
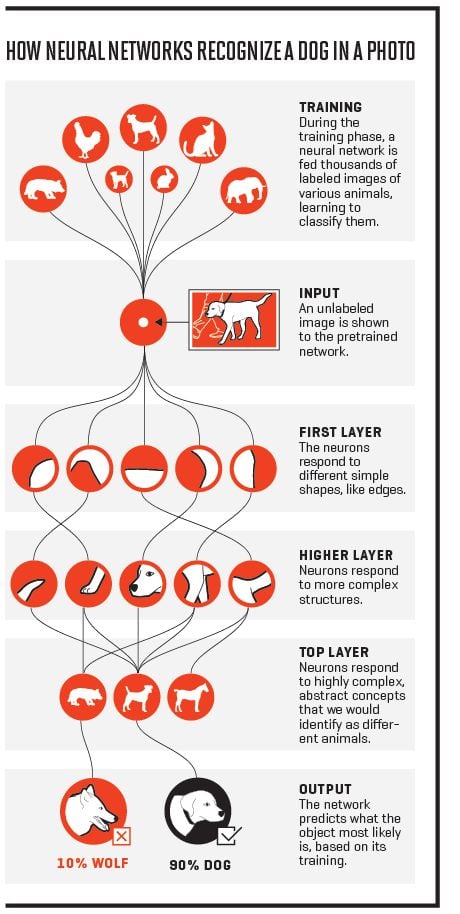
A neural network consists of layers of nodes, which receive stimulation from “trigger” data. This data then is assigned a weight through coefficients, as some data inputs may be more significant than others.
Neurons normally come in three different layers: an input layer of data, a hidden layer with mathematical computations, and an output layer. In an example where we want to estimate airline ticket prices, our input layer would collect the origin airport, destination airport, departure date, and airline. Each of those would receive a weight (perhaps the departure date matters more than the airline) and then the output would deliver a price prediction.
(Source.)
Natural Language Processing
Natural language processing is the subfield of AI that processes human languages. It is a very important term in the field of data science and machine learning. The challenge is that often human speech is not literal. There are figures of speech, words, or phrasing specific to certain dialects and cultures, and sentences that can take on different meanings with grammar and punctuation. Similar to human conversations, natural language processors need to use the syntax (arrangement of words) and semantics (meaning of that arrangement) to come up with correct interpretations.
The first step in natural language processing is converting unstructured language data into a form that can be read by a computer. The computer then assigns meaning to each sentence through algorithms and translates it back, often in another form (for example, speech to text or from one language to another).
Natural language processing can help translation apps like Google Translate, document collaboration and communication tools like Slack and Microsoft Word, and virtual assistants. Here’s an example of how the Royal Bank of Scotland incorporates text analytics to parse through customer service complaints from emails, surveys, and call centers to isolate problem areas and enact improvements to their relationships and reputation.
Machine Vision
Machine vision, or computer vision, is the process by which machines can capture and analyze images. This allows for the diagnosis of skin cancer by looking at X-rays and other medical imagery, and for the detection of real-time traffic and vehicle types for self-driving cars, like Tesla’s new models.
There are many different ways that machines can “see”: representing colors numerically, decomposing images into different parts, and identifying corners, edges, and textures. As the machines gather and code more information, they begin to view the larger picture.
Many of the trends around machine vision right now include integration into the industrial internet of things, which involves collecting productivity inputs and sensory data in factories, and non-industrial applications like “driverless cars, autonomous farm equipment, drone applications, intelligent traffic systems, and guided surgery.”
Machine Learning Engineer
With all these exciting technological advances, who is responsible for deploying ML within companies? In many cases, the responsibility first lies with the machine learning engineer, a data-driven software engineer focused on building the systems that can eventually learn and perform work autonomously. These engineers usually need to be familiar with different code bases, distributed computing, data wrangling, and computer science.
Here’s a snapshot from Springboard on what it takes to become a leading machine learning engineer. And here’s an explanation from a machine learning engineer.
Machine learning is on the rise, with 96% of companies increasing investments in this area by 2020. According to Indeed, machine learning is the No. 1 in-demand AI skill and the global market is predicted to increase sevenfold, from $1.4 billion in 2017 to $8.8 billion by 2022.
One of the main challenges with machine learning today is the small talent pool—according to Element AI, there are fewer than 10,000 people worldwide with the necessary skills. That means people with the right skills can enjoy competitive salaries and job security.
Companies are no longer just collecting data. They’re seeking to use it to outpace competitors, especially with the rise of AI and advanced analytics techniques. Between organizations and these techniques are the data scientists – the experts who crunch numbers and translate them into actionable strategies. The future, it seems, belongs to those who can decipher the story hidden within the data, making the role of data scientists more important than ever.
In this article, we’ll look at 13 careers in data science, analyzing the roles and responsibilities and how to land that specific job in the best way. Whether you’re more drawn out to the creative side or interested in the strategy planning part of data architecture, there’s a niche for you.
Is Data Science A Good Career?
Yes. Besides being a field that comes with competitive salaries, the demand for data scientists continues to increase as they have an enormous impact on their organizations. It’s an interdisciplinary field that keeps the work varied and interesting.
10 Data Science Careers To Consider
Whether you want to change careers or land your first job in the field, here are 13 of the most lucrative data science careers to consider.
Data Scientist
Data scientists represent the foundation of the data science department. At the core of their role is the ability to analyze and interpret complex digital data, such as usage statistics, sales figures, logistics, or market research – all depending on the field they operate in.
They combine their computer science, statistics, and mathematics expertise to process and model data, then interpret the outcomes to create actionable plans for companies.
General Requirements
A data scientist’s career starts with a solid mathematical foundation, whether it’s interpreting the results of an A/B test or optimizing a marketing campaign. Data scientists should have programming expertise (primarily in Python and R) and strong data manipulation skills.
Although a university degree is not always required beyond their on-the-job experience, data scientists need a bunch of data science courses and certifications that demonstrate their expertise and willingness to learn.
Average Salary
The average salary of a data scientist in the US is $156,363 per year.
Data Analyst
A data analyst explores the nitty-gritty of data to uncover patterns, trends, and insights that are not always immediately apparent. They collect, process, and perform statistical analysis on large datasets and translate numbers and data to inform business decisions.
A typical day in their life can involve using tools like Excel or SQL and more advanced reporting tools like Power BI or Tableau to create dashboards and reports or visualize data for stakeholders. With that in mind, they have a unique skill set that allows them to act as a bridge between an organization’s technical and business sides.
General Requirements
To become a data analyst, you should have basic programming skills and proficiency in several data analysis tools. A lot of data analysts turn to specialized courses or data science bootcamps to acquire these skills.
For example, Coursera offers courses like Google’s Data Analytics Professional Certificate or IBM’s Data Analyst Professional Certificate, which are well-regarded in the industry. A bachelor’s degree in fields like computer science, statistics, or economics is standard, but many data analysts also come from diverse backgrounds like business, finance, or even social sciences.
Average Salary
The average base salary of a data analyst is $76,892 per year.
Business Analyst
Business analysts often have an essential role in an organization, driving change and improvement. That’s because their main role is to understand business challenges and needs and translate them into solutions through data analysis, process improvement, or resource allocation.
A typical day as a business analyst involves conducting market analysis, assessing business processes, or developing strategies to address areas of improvement. They use a variety of tools and methodologies, like SWOT analysis, to evaluate business models and their integration with technology.
General Requirements
Business analysts often have related degrees, such as BAs in Business Administration, Computer Science, or IT. Some roles might require or favor a master’s degree, especially in more complex industries or corporate environments.
Employers also value a business analyst’s knowledge of project management principles like Agile or Scrum and the ability to think critically and make well-informed decisions.
Average Salary
A business analyst can earn an average of $84,435 per year.
Database Administrator
The role of a database administrator is multifaceted. Their responsibilities include managing an organization’s database servers and application tools.
A DBA manages, backs up, and secures the data, making sure the database is available to all the necessary users and is performing correctly. They are also responsible for setting up user accounts and regulating access to the database. DBAs need to stay updated with the latest trends in database management and seek ways to improve database performance and capacity. As such, they collaborate closely with IT and database programmers.
General Requirements
Becoming a database administrator typically requires a solid educational foundation, such as a BA degree in data science-related fields. Nonetheless, it’s not all about the degree because real-world skills matter a lot. Aspiring database administrators should learn database languages, with SQL being the key player. They should also get their hands dirty with popular database systems like Oracle and Microsoft SQL Server.
Average Salary
Database administrators earn an average salary of $77,391 annually.
Data Engineer
Successful data engineers construct and maintain the infrastructure that allows the data to flow seamlessly. Besides understanding data ecosystems on the day-to-day, they build and oversee the pipelines that gather data from various sources so as to make data more accessible for those who need to analyze it (e.g., data analysts).
General Requirements
Data engineering is a role that demands not just technical expertise in tools like SQL, Python, and Hadoop but also a creative problem-solving approach to tackle the complex challenges of managing massive amounts of data efficiently.
Usually, employers look for credentials like university degrees or advanced data science courses and bootcamps.
Average Salary
Data engineers earn a whooping average salary of $125,180 per year.
Database Architect
A database architect’s main responsibility involves designing the entire blueprint of a data management system, much like an architect who sketches the plan for a building. They lay down the groundwork for an efficient and scalable data infrastructure.
Their day-to-day work is a fascinating mix of big-picture thinking and intricate detail management. They decide how to store, consume, integrate, and manage data by different business systems.
General Requirements
If you’re aiming to excel as a database architect but don’t necessarily want to pursue a degree, you could start honing your technical skills. Become proficient in database systems like MySQL or Oracle, and learn data modeling tools like ERwin. Don’t forget programming languages – SQL, Python, or Java.
If you want to take it one step further, pursue a credential like the Certified Data Management Professional (CDMP) or the Data Science Bootcamp by Springboard.
Average Salary
Data architecture is a very lucrative career. A database architect can earn an average of $165,383 per year.
Machine Learning Engineer
A machine learning engineer experiments with various machine learning models and algorithms, fine-tuning them for specific tasks like image recognition, natural language processing, or predictive analytics. Machine learning engineers also collaborate closely with data scientists and analysts to understand the requirements and limitations of data and translate these insights into solutions.
General Requirements
As a rule of thumb, machine learning engineers must be proficient in programming languages like Python or Java, and be familiar with machine learning frameworks like TensorFlow or PyTorch. To successfully pursue this career, you can either choose to undergo a degree or enroll in courses and follow a self-study approach.
Average Salary
Depending heavily on the company’s size, machine learning engineers can earn between $125K and $187K per year, one of the highest-paying AI careers.
Quantitative Analyst
Qualitative analysts are essential for financial institutions, where they apply mathematical and statistical methods to analyze financial markets and assess risks. They are the brains behind complex models that predict market trends, evaluate investment strategies, and assist in making informed financial decisions.
They often deal with derivatives pricing, algorithmic trading, and risk management strategies, requiring a deep understanding of both finance and mathematics.
General Requirements
This data science role demands strong analytical skills, proficiency in mathematics and statistics, and a good grasp of financial theory. It always helps if you come from a finance-related background.
Average Salary
A quantitative analyst earns an average of $173,307 per year.
Data Mining Specialist
A data mining specialist uses their statistics and machine learning expertise to reveal patterns and insights that can solve problems. They swift through huge amounts of data, applying algorithms and data mining techniques to identify correlations and anomalies. In addition to these, data mining specialists are also essential for organizations to predict future trends and behaviors.
General Requirements
If you want to land a career in data mining, you should possess a degree or have a solid background in computer science, statistics, or a related field.
Average Salary
Data mining specialists earn $109,023 per year.
Data Visualisation Engineer
Data visualisation engineers specialize in transforming data into visually appealing graphical representations, much like a data storyteller. A big part of their day involves working with data analysts and business teams to understand the data’s context.
General Requirements
Data visualization engineers need a strong foundation in data analysis and be proficient in programming languages often used in data visualization, such as JavaScript, Python, or R. A valuable addition to their already-existing experience is a bit of expertise in design principles to allow them to create visualizations.
Average Salary
The average annual pay of a data visualization engineer is $103,031.
Resources To Find Data Science Jobs
The key to finding a good data science job is knowing where to look without procrastinating. To make sure you leverage the right platforms, read on.
Job Boards
When hunting for data science jobs, both niche job boards and general ones can be treasure troves of opportunity.
Niche boards are created specifically for data science and related fields, offering listings that cut through the noise of broader job markets. Meanwhile, general job boards can have hidden gems and opportunities.
Online Communities
Spend time on platforms like Slack, Discord, GitHub, or IndieHackers, as they are a space to share knowledge, collaborate on projects, and find job openings posted by community members.
Network And LinkedIn
Don’t forget about socials like LinkedIn or Twitter. The LinkedIn Jobs section, in particular, is a useful resource, offering a wide range of opportunities and the ability to directly reach out to hiring managers or apply for positions. Just make sure not to apply through the “Easy Apply” options, as you’ll be competing with thousands of applicants who bring nothing unique to the table.
FAQs about Data Science Careers
We answer your most frequently asked questions.
Do I Need A Degree For Data Science?
A degree is not a set-in-stone requirement to become a data scientist. It’s true many data scientists hold a BA’s or MA’s degree, but these just provide foundational knowledge. It’s up to you to pursue further education through courses or bootcamps or work on projects that enhance your expertise. What matters most is your ability to demonstrate proficiency in data science concepts and tools.
Does Data Science Need Coding?
Yes. Coding is essential for data manipulation and analysis, especially knowledge of programming languages like Python and R.
Is Data Science A Lot Of Math?
It depends on the career you want to pursue. Data science involves quite a lot of math, particularly in areas like statistics, probability, and linear algebra.
What Skills Do You Need To Land an Entry-Level Data Science Position?
To land an entry-level job in data science, you should be proficient in several areas. As mentioned above, knowledge of programming languages is essential, and you should also have a good understanding of statistical analysis and machine learning. Soft skills are equally valuable, so make sure you’re acing problem-solving, critical thinking, and effective communication.
Since you’re here…Are you interested in this career track? Investigate with our free guide to what a data professional actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp which will help you land a job or your tuition back!