![What is Data Science [2022 Guide]](https://www.springboard.com/blog/wp-content/uploads/2016/11/what-is-data-science-2022-guide.png)
The proliferation of data has made data science an attractive career choice. US News ranks data scientist at #3 on its list of the best jobs in technology, and at #6 among all jobs. There has been a 650% increase in data science jobs since 2012 and another 11.5 million jobs are expected to be added by 2026.
With everything that’s happening in the data science industry, you’re probably curious about what data scientists actually do. That’s what we’ll cover in this post: the data science process, the differences between similar roles, and the kinds of skills you’ll need to land a data science job.
What Is Data Science?
Data science is the practice of analyzing large volumes of often unstructured data, with the goal of producing meaningful insights.
Data science approaches, algorithms, and tools can be applied to all kinds of business problems. You can use data to optimize sales funnels, learn which customer segments prefer which products, find the kinds of discounts the customers appreciate the most, and so on. Data science can also be applied to the internal operations of a company to enhance its productivity.
The Value of Data
It is estimated that a whopping 200 zettabytes of data (or 2 x 10^14 gigabytes) will be in cloud storage by 2025. In its 2021 Global Data Protection Index, Dell said that the volume of data that companies handle has grown tenfold in just five years.
These huge volumes of data don’t offer us any value without interpretation. They’re often unstructured, have corrupted entries, and are not easy to interpret. However, thanks to data science, all of that data can be used to develop profitable strategies and identify new opportunities.
How Is Data Science Used in Real Life

Because of data science, otherwise onerous volumes of data have become essential. But how exactly do companies leverage expertise in data science to get the information that they want? Let’s take a look at a few real-world examples of data science in action.
Targeted Ads
What people do while using social media and other websites produces a lot of valuable data. Every time you click, a new data point is created. Companies use this information to learn more about their users.
These insights often inform targeted ads, in which users are shown products and services that are tailored to their needs and interests. The ability to apply data science to advertising has resulted in higher click-through rates and more efficient advertising models.
Recommendation Engines
Many websites tailor their recommendations to each user. Netflix, for example, will recommend shows that are likely to be of interest. Amazon likewise knows that it can vastly improve its sales volumes if buyers see the right product at the right time.
Data science is essential in the construction of recommendation engines. It isn’t possible to predict the future, but you can make well-informed guesses by studying the data produced by users and making recommendations based on your offerings.
Image Recognition

When you upload a picture to Facebook, the platform identifies the people in it with a surprising degree of accuracy. This works by applying data science to images, which is known as image recognition.
Image recognition has become increasingly powerful as more visual data is produced every day. Big companies can now identify each individual object in an image and classify groups of images accurately. This also has applications in the medical field, where it is being used to analyze X-rays and detect tumors in radio imaging.
Fraud Detection
Companies have been able to use data science to build highly accurate fraud detection models and put preemptive measures in place to reduce fraud. Let’s take insurance fraud for example. Insurance companies can access all kinds of data on their customers and the claims that they make. They combine this data with predictive data analytics to identify the characteristics of normal claims and reduce fraudulent incidents.
Dating App Algorithms
Dating apps need to show their users people who they are most likely to connect with. Continued engagement on these apps depends on regular matches, and users interacting in meaningful ways. As a result, dating apps have turned to data science to learn more about their users and their interests.
Dating apps have access to all kinds of user data. That includes educational information, hobbies, and work history. They process this data and build an algorithm that shows users the profiles with which they are most likely to match.
The Data Science Process
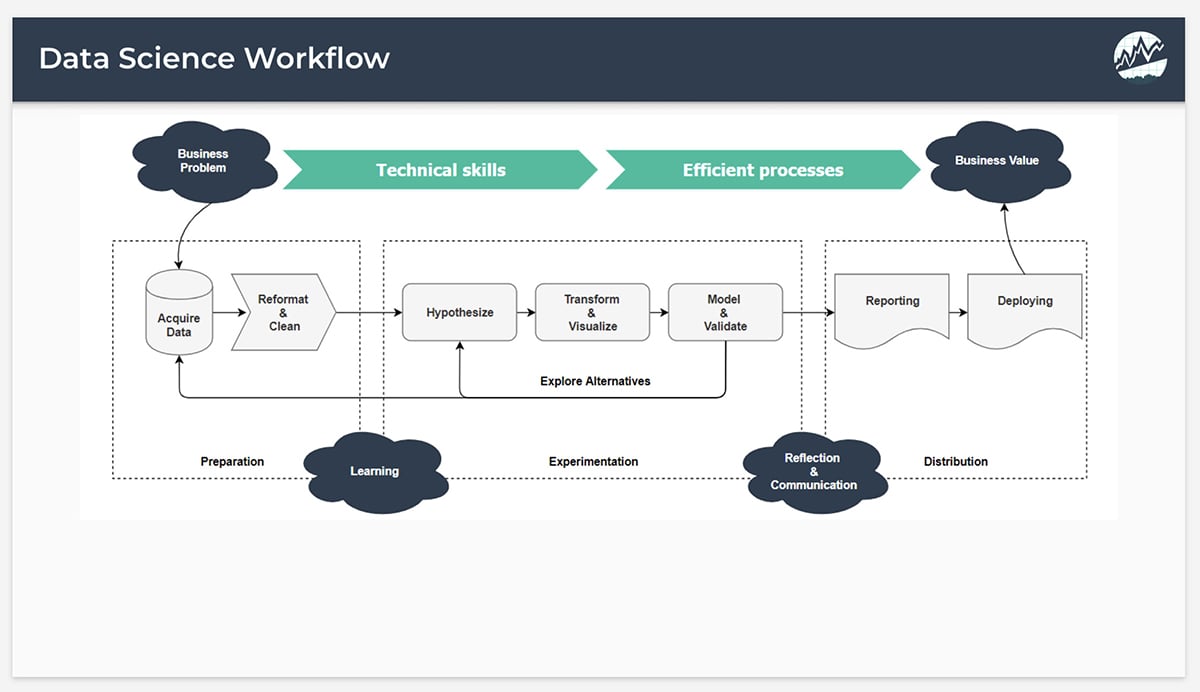
It’s clear from these examples that data is everywhere. Now let’s look at how inscrutable data is turned into information that can guide business decisions.
Framing the Problem
Every data science project starts by framing the problem at hand. Before you begin working on your project, you have to contextualize the problem within the larger organizational goals. It’s also important to frame the problem in a concrete manner. What is the business looking to achieve? What are its goals and what challenges does it face? Answering these questions can help you set the correct tone for the project.
Get To Know Other Data Science Students

Haotian Wu
Data Scientist at RepTrak

Jonathan King
Sr. Healthcare Analyst at IBM

Melanie Hanna
Data Scientist at Farmer's Fridge
Data Collection
Now it’s time to collect the data that can help you solve a problem. You can use either internal company data or publicly available data sets. Be cognizant of the kinds of resources that are available on a given project. You have to determine what kind of investment of finances and time is required to obtain the data that you’ll need.
Data Cleaning

When you first get your data, it’s not yet going to be amenable to analysis. You need to clean the data to eliminate redundancies, remove corrupt entries, and fill in missing values using heuristic methods.
There are various ways in which you can clean data. Learn about this in more detail here.
High-level Analysis
Once you have your data ready, you can glean some insights through some high-level exploratory analysis. This will unearth some of the more obvious patterns that are present in the dataset. Not only does this help you quickly glean some useful insights, but it can also guide the rest of the process, in terms of the trends you look for or the characteristics you study in detail.
In-depth Data Analysis
This is where all of the heavy-duty data analysis is performed. First, you have to be careful to choose the right tools for data analysis. There are lots of different artificial intelligence techniques and analytics tools that you can use to extract insights from data. But you have to justify the use of each algorithm based on how it matches the problem that you’re trying to solve.
For example, let’s say you’re trying to forecast the success of a new product. In that case, you would have to build a predictive model and choose the right feature vectors and algorithms. It’s easy to get distracted by all the tools at your disposal, so stay on track by focusing on the problem at hand.
Communicating Results
The final stage of the data science process involves sharing your findings with other stakeholders. This is a highly underrated soft skill in the industry and one that will make your overall job easier.
The goal is to condense the work you’ve done into its most important points. You might use visualizations to convey trends in a way that non-technical staff can understand. These skills are known as data storytelling.
What Makes Data Science Different?

There are a few data-related disciplines with similar-sounding names that also have overlapping responsibilities. Let’s learn about their definitive characteristics so that we can understand where data scientists fit into a technology team.
Data Science vs Data Analytics
Data science is a broad field that uses computer science, math, and machine learning to explore correlations and patterns in large volumes of data. Data analytics is more focused on answering specific questions using data (see our guide to Data Science vs Data Analytics here).
Data Science vs Machine Learning
Machine learning is the enabling of computers to obtain insights from data. Data scientists use machine learning techniques as part of their work.
Data Science vs Artificial Intelligence

Artificial intelligence encompasses a certain set of algorithms that can help computers autonomously make observations about datasets. Data science is a much broader field and covers business insights, data analysis, and visualization.
Understanding the Data Scientist
What Does a Data Scientist Do?
Data scientists have the following roles and responsibilities with an organization:
- Identify business areas that can be enriched by data analysis
- Select sources for data and obtain data for different projects
- Conduct data wrangling and ensure data is clean before analysis
- Perform exploratory data analysis to find correlations within data
- Build statistical models and machine learning algorithms that can enhance the data analysis process
- Present findings to stakeholders in the company using data storytelling
Data Science Tools

Data scientists use various tools to set workflows and automate processes in the data science industry. Here are some of the most popular ones.
MATLAB
MATLAB is used for mathematical research. In data science, it simulates neural networks and statistical models.
Microsoft Excel
The humble Microsoft Excel is a powerful data analysis tool and is widely used by professionals in the field.
Apache Spark
This is a tool that’s well-known in data science circles for its machine learning APIs. Spark is also used for batch processing data.
Tableau
Tableau is one of the most popular data visualization tools in the world. It can be used to depict data in various forms (charts, graphics, etc) and to build powerful dashboards.
Data Science Career Opportunities
Data Scientist
What they do
Data scientists source data, clean it, then develop models and algorithms to unearth patterns in their data.
Organizational role
Data scientists are tasked with identifying opportunities to use data to solve business problems.
Related Read: Data Scientist Job Description
Skills needed
- Statistical analysis and computing
- Data wrangling
- Data storytelling
Data Analyst
What they do
Data analysts analyze datasets and solve specific business problems.
Organizational role
Data analysts help businesses find solutions to problems in sales, customer segments, and industry trends.
Skills needed
- Linear algebra, probability, and other foundational math
- Programming languages like Python and R
- Critical thinking and problem solving
Data Engineer
What they do
Data engineers construct the software infrastructure to store, retrieve, and process data for data science projects.
Organizational role
Data engineers ensure data reliability and quality. They receive the requirements for projects from data scientists and go about building the software architecture for it.
Skills needed
- Data warehousing
- Software and database architectures
- Data extraction, transformation, loading (ETL) processes
Getting Into Data Science

We now know everything that we need to know about data science and its role in a business setting. You’re probably wondering how you can break into the field yourself, so here are a few pointers.
What Skills Will You Need?
Math
Data scientists need to be conversant in mathematical concepts. You can start by working towards a foundational understanding of linear algebra, calculus, statistics, and probability.
Programming
You will be required to translate your mathematical skills into programs. The most popular languages in data science are Python and R.
Machine Learning
Data scientists use machine learning models extensively. Beginners need to know how to use techniques like logistic regression, decision trees, and support vector machines.
Data Storytelling
Data scientists have to know what kinds of visualizations (graphs, charts, etc) are best suited to different kinds of data. Data storytelling also requires presentation skills, which you can hone by practicing your public speaking skills and conducting presentations regularly.
What Background Is Preferable?

Data scientists usually have degrees in the math or computer science field. Most companies will require you to have a degree.
If you don’t have a degree in a relevant field, you can make progress by attending a bootcamp or completing a data science course. You can also work on your own projects to increase your chances of breaking into the data science industry.
What Will You Learn?
Data scientists pick up skills in a wide variety of areas. Their core job involves using mathematical and computational approaches to study data sets. But they also gain a strong grasp of how data is used and what kinds of problems can be solved by leveraging it.
Finally, there are various soft skills that you can gain with a data science job. Data scientists work in highly collaborative environments and constantly interact with various other teams in their companies.
FAQs About Data Science
Who Is Eligible for a Career in Data Science?
Individuals with an academic background in math or computer sciences can land a job in data science easily. However, it is also possible to get recruited by completing data science courses and building your own projects.
Can an Average Student Become a Data Scientist?
Yes, an average student can become a data scientist. You can improve your skills by working through courses offered outside college and working on projects that challenge you.
Which Degree Is Best To Become a Data Scientist?
A bachelor’s degree in computer science or math discipline is a strong base for a career in data science.
Since you’re here…
Curious about a career in data science? Experiment with our free data science learning path, or join our Data Science Bootcamp, where you’ll get your tuition back if you don’t land a job after graduating. We’re confident because our courses work – check out our student success stories to get inspired.


