Bryan Dickinson is not one to shy away from trying different things. While earning his undergraduate degree in Exercise Physiology, he worked as a personal trainer, creating personalized fitness programs for his clients. He had always loved working with people, so he happily took to a career in retail management after graduating from college at the height of the economic recession in 2008. While at Nordstrom, he quickly rose up the ranks from customer service representative all the way to service experience manager.
Despite his meandering career path, Bryan always found himself as the go-to person when his coworkers had questions about Excel spreadsheets or data-related questions. For some reason, he couldn’t shake the memory of a kinesiology class he took in college and one class assignment in particular that required him to compile a lot of data and perform A/B tests.
“Thinking back, I loved that project so much, but I didn’t really understand why,” he shared. Once he started doing research into data science careers, he was hooked.
Now, he’s a senior marketing analyst at REI, an outdoor recreational equipment retailer, and recently won a hackathon, which he participated in with five other Springboard students. The group worked on a project for two months to investigate the factors contributing to water pollution along the Chesapeake Bay, the largest estuary in the United States, stretching from Cooperstown, New York, to Norfolk, Virginia. His team won after they created a machine learning model that could predict water pollution at different locations along the Bay. He says winning the hackathon gave him the confidence to solve problems using data even in areas where he lacks domain knowledge.
“It was super fun and kind of reaffirming that we have the data and the skills and experience to put something like this together, even if we didn’t know much about environmental science,” he said.

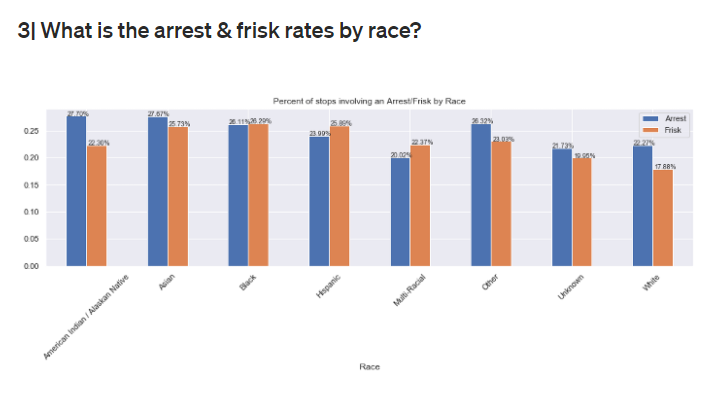 There were a lot of reports about racial profiling and police using excessive force. My conclusion was that even if the Seattle Police Department as a whole isn’t necessarily racist, an individual can still be racist. So an option for further study is to compare individual police officers to see if they have a trend of stopping more minorities than others.
There are also other factors to think about, like what constitutes a stop and what constitutes a frisk, each of which requires a certain type of training. How are officers learning this and what kinds of biases go into that training?
There were a lot of reports about racial profiling and police using excessive force. My conclusion was that even if the Seattle Police Department as a whole isn’t necessarily racist, an individual can still be racist. So an option for further study is to compare individual police officers to see if they have a trend of stopping more minorities than others.
There are also other factors to think about, like what constitutes a stop and what constitutes a frisk, each of which requires a certain type of training. How are officers learning this and what kinds of biases go into that training?




