
Machine learning interview questions are an integral part of the data science interview and the path to becoming a data scientist, machine learning engineer, or data engineer.
Springboard has created a free guide to data science interviews, where we learned exactly how these interviews are designed to trip up candidates! In this blog, we have curated a list of 51 key machine learning interview questions that you might encounter in a machine learning interview. We’ve also provided some handy answers to go along with them so you can ace your machine learning job interview (or machine learning internship).
If you’re looking for a more comprehensive insight into machine learning career options, check out our guides on how to become a data scientist and how to become a data engineer.
Finally, don’t forget to check out Springboard’s Machine Learning Engineering Career Track.
Machine Learning Interview Questions: 4 Categories
We’ve traditionally seen machine learning interview questions pop up in several categories.
- The first really has to do with the algorithms and theory behind machine learning. You’ll have to show an understanding of how algorithms compare with one another and how to measure their efficacy and accuracy in the right way.
- The second category has to do with your programming skills and your ability to execute on top of those algorithms and the theory.
- The third has to do with your general interest in machine learning. You’ll be asked about what’s going on in the industry and how you keep up with the latest machine learning trends.
- Finally, there are company or industry-specific questions that test your ability to take your general machine learning knowledge and turn it into actionable points to drive the bottom line forward.
We’ve divided this guide to machine learning interview questions into the categories we mentioned above so that you can more easily get to the information you need when it comes to machine learning interview questions.

Become a Data Scientist. Land a Job or Your Money Back.
Build job-ready skills with 28 mini-projects, three capstones, and an advanced specialization project. Work 1:1 with an industry mentor. Land a job — or your money back.
Machine Learning Interview Questions: Algorithms/Theory
Machine learning interview questions about ML algorithms will test your grasp of the theory behind machine learning.
Q1: What’s the trade-off between bias and variance?
Answer: Bias is error due to erroneous or overly simplistic assumptions in the learning algorithm you’re using. This can lead to the model underfitting your data, making it hard for it to have high predictive accuracy and for you to generalize your knowledge from the training set to the test set.
Variance is error due to too much complexity in the learning algorithm you’re using. This leads to the algorithm being highly sensitive to high degrees of variation in your training data, which can lead your model to overfit the data. You’ll be carrying too much noise from your training data for your model to be very useful for your test data.
The bias-variance decomposition essentially decomposes the learning error from any algorithm by adding the bias, the variance and a bit of irreducible error due to noise in the underlying dataset. Essentially, if you make the model more complex and add more variables, you’ll lose bias but gain some variance — in order to get the optimally reduced amount of error, you’ll have to tradeoff bias and variance. You don’t want either high bias or high variance in your model.
More reading: Bias-Variance Tradeoff (Wikipedia)
Q2: What is the difference between supervised and unsupervised machine learning?
Answer: Supervised learning requires training labeled data. For example, in order to do classification (a supervised learning task), you’ll need to first label the data you’ll use to train the model to classify data into your labeled groups. Unsupervised learning, in contrast, does not require labeling data explicitly.
More reading: Classic examples of supervised vs. unsupervised learning (Springboard)
Q3: How is KNN different from k-means clustering?
Answer: K-Nearest Neighbors is a supervised classification algorithm, while k-means clustering is an unsupervised clustering algorithm. While the mechanisms may seem similar at first, what this really means is that in order for K-Nearest Neighbors to work, you need labeled data you want to classify an unlabeled point into (thus the nearest neighbor part). K-means clustering requires only a set of unlabeled points and a threshold: the algorithm will take unlabeled points and gradually learn how to cluster them into groups by computing the mean of the distance between different points.
The critical difference here is that KNN needs labeled points and is thus supervised learning, while k-means doesn’t—and is thus unsupervised learning.
More reading: How is the k-nearest neighbor algorithm different from k-means clustering? (Quora)
Q4: Explain how a ROC curve works.
Answer: The ROC curve is a graphical representation of the contrast between true positive rates and the false positive rate at various thresholds. It’s often used as a proxy for the trade-off between the sensitivity of the model (true positives) vs the fall-out or the probability it will trigger a false alarm (false positives).
More reading: Receiver operating characteristic (Wikipedia)
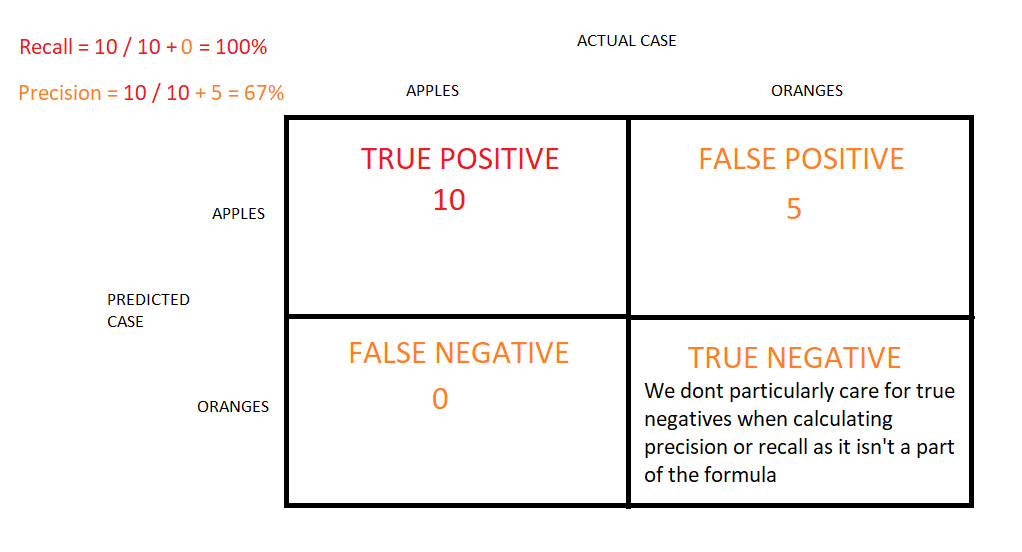
Q5: Define precision and recall.
Answer: Recall is also known as the true positive rate: the amount of positives your model claims compared to the actual number of positives there are throughout the data. Precision is also known as the positive predictive value, and it is a measure of the amount of accurate positives your model claims compared to the number of positives it actually claims. It can be easier to think of recall and precision in the context of a case where you’ve predicted that there were 10 apples and 5 oranges in a case of 10 apples. You’d have perfect recall (there are actually 10 apples, and you predicted there would be 10) but 66.7% precision because out of the 15 events you predicted, only 10 (the apples) are correct.
Explanation: Out of a sample size of 15 (10 apples + 5 oranges), you have identified 10 apples as apples BUT you have also incorrectly predicted 5 oranges as apples. This implies that the true positive figure is 10 (10 correctly identified apples), whereas the false positive figure is 5 (5 oranges incorrectly tagged as apples).
As per the formula of Precision = True Positive / (True Positive + False Positive), therefore the precision rate is 67%.
As per the Recall formula = True Positive / (True Positive + False Negative), hence the recall rate is 100%. This is because not a single apple was incorrectly predicted as an orange.
More reading: Precision and recall (Wikipedia)
Q6: What is Bayes’ Theorem? How is it useful in a machine learning context?
Answer: Bayes’ Theorem gives you the posterior probability of an event given what is known as prior knowledge.
Mathematically, it’s expressed as the true positive rate of a condition sample divided by the sum of the false positive rate of the population and the true positive rate of a condition. Say you had a 60% chance of actually having the flu after a flu test, but out of people who had the flu, the test will be false 50% of the time, and the overall population only has a 5% chance of having the flu. Would you actually have a 60% chance of having the flu after having a positive test?
Bayes’ Theorem says no. It says that you have a (.6 * 0.05) (True Positive Rate of a Condition Sample) / (.6*0.05)(True Positive Rate of a Condition Sample) + (.5*0.95) (False Positive Rate of a Population) = 0.0594 or 5.94% chance of getting a flu.
Bayes’ Theorem is the basis behind a branch of machine learning that most notably includes the Naive Bayes classifier. That’s something important to consider when you’re faced with machine learning interview questions.
More reading: An Intuitive (and Short) Explanation of Bayes’ Theorem (BetterExplained)
Get To Know Other Data Science Students

Mengqin (Cassie) Gong
Data Scientist at Whatsapp

Nick Lenczewski
Data Scientist at Ovative Group

Melanie Hanna
Data Scientist at Farmer's Fridge
Q7: Why is “Naive” Bayes naive?
Answer: Despite its practical applications, especially in text mining, Naive Bayes is considered “Naive” because it makes an assumption that is virtually impossible to see in real-life data: the conditional probability is calculated as the pure product of the individual probabilities of components. This implies the absolute independence of features — a condition probably never met in real life.
As a Quora commenter put it whimsically, a Naive Bayes classifier that figured out that you liked pickles and ice cream would probably naively recommend you a pickle ice cream.
More reading: Why is “naive Bayes” naive? (Quora)
Q8: Explain the difference between L1 and L2 regularization.
Answer: L2 regularization tends to spread error among all the terms, while L1 is more binary/sparse, with many variables either being assigned a 1 or 0 in weighting. L1 corresponds to setting a Laplacean prior on the terms, while L2 corresponds to a Gaussian prior.
More reading: What is the difference between L1 and L2 regularization? (Quora)
Q9: What’s your favorite algorithm, and can you explain it to me in less than a minute?
Answer: Interviewers ask such machine learning interview questions to test your understanding of how to communicate complex and technical nuances with poise and the ability to summarize quickly and efficiently. While answering such questions, make sure you have a choice and ensure you can explain different algorithms so simply and effectively that a five-year-old could grasp the basics!
Q10: What’s the difference between Type I and Type II error?
Answer: Don’t think that this is a trick question! Many machine learning interview questions will be an attempt to lob basic questions at you just to make sure you’re on top of your game and you’ve prepared all of your bases.
Type I error is a false positive, while Type II error is a false negative. Briefly stated, Type I error means claiming something has happened when it hasn’t, while Type II error means that you claim nothing is happening when in fact something is.
A clever way to think about this is to think of Type I error as telling a man he is pregnant, while Type II error means you tell a pregnant woman she isn’t carrying a baby.
More reading: Type I and type II errors (Wikipedia)
Q11: What’s a Fourier transform?
Answer: A Fourier transform is a generic method to decompose generic functions into a superposition of symmetric functions. Or as this more intuitive tutorial puts it, given a smoothie, it’s how we find the recipe. The Fourier transform finds the set of cycle speeds, amplitudes, and phases to match any time signal. A Fourier transform converts a signal from time to frequency domain—it’s a very common way to extract features from audio signals or other time series such as sensor data.
More reading: Fourier transform (Wikipedia)
Q12: What’s the difference between probability and likelihood?
More reading: What is the difference between “likelihood” and “probability”? (Cross Validated)
Q13: What is deep learning, and how does it contrast with other machine learning algorithms?
Answer: Deep learning is a subset of machine learning that is concerned with neural networks: how to use backpropagation and certain principles from neuroscience to more accurately model large sets of unlabelled or semi-structured data. In that sense, deep learning represents an unsupervised learning algorithm that learns representations of data through the use of neural nets.
More reading: Deep learning (Wikipedia)
Q14: What’s the difference between a generative and discriminative model?
Answer: A generative model will learn categories of data while a discriminative model will simply learn the distinction between different categories of data. Discriminative models will generally outperform generative models on classification tasks.
More reading: What is the difference between a Generative and Discriminative Algorithm? (Stack Overflow)
Q15: What cross-validation technique would you use on a time series dataset?
Answer: Instead of using standard k-folds cross-validation, you have to pay attention to the fact that a time series is not randomly distributed data—it is inherently ordered by chronological order. If a pattern emerges in later time periods, for example, your model may still pick up on it even if that effect doesn’t hold in earlier years!
You’ll want to do something like forward chaining where you’ll be able to model on past data then look at forward-facing data.
- Fold 1 : training [1], test [2]
- Fold 2 : training [1 2], test [3]
- Fold 3 : training [1 2 3], test [4]
- Fold 4 : training [1 2 3 4], test [5]
- Fold 5 : training [1 2 3 4 5], test [6]
More reading: Using k-fold cross-validation for time-series model selection (CrossValidated)
Q16: How is a decision tree pruned?
Answer: Pruning is what happens in decision trees when branches that have weak predictive power are removed in order to reduce the complexity of the model and increase the predictive accuracy of a decision tree model. Pruning can happen bottom-up and top-down, with approaches such as reduced error pruning and cost complexity pruning.
Reduced error pruning is perhaps the simplest version: replace each node. If it doesn’t decrease predictive accuracy, keep it pruned. While simple, this heuristic actually comes pretty close to an approach that would optimize for maximum accuracy.
More reading: Pruning (decision trees)
Q17: Which is more important to you: model accuracy or model performance?
Answer: Such machine learning interview questions tests your grasp of the nuances of machine learning model performance! Machine learning interview questions often look towards the details. There are models with higher accuracy that can perform worse in predictive power—how does that make sense?
Well, it has everything to do with how model accuracy is only a subset of model performance, and at that, a sometimes misleading one. For example, if you wanted to detect fraud in a massive dataset with a sample of millions, a more accurate model would most likely predict no fraud at all if only a vast minority of cases were fraud. However, this would be useless for a predictive model—a model designed to find fraud that asserted there was no fraud at all! Questions like this help you demonstrate that you understand model accuracy isn’t the be-all and end-all of model performance.
More reading: Accuracy paradox (Wikipedia)
Q18: What’s the F1 score? How would you use it?
Answer: The F1 score is a measure of a model’s performance. It is a weighted average of the precision and recall of a model, with results tending to 1 being the best, and those tending to 0 being the worst. You would use it in classification tests where true negatives don’t matter much.
More reading: F1 score (Wikipedia)
Q19: How would you handle an imbalanced dataset?
Answer: An imbalanced dataset is when you have, for example, a classification test and 90% of the data is in one class. That leads to problems: an accuracy of 90% can be skewed if you have no predictive power on the other category of data! Here are a few tactics to get over the hump:
- Collect more data to even the imbalances in the dataset.
- Resample the dataset to correct for imbalances.
- Try a different algorithm altogether on your dataset.
What’s important here is that you have a keen sense for what damage an unbalanced dataset can cause, and how to balance that.
More reading: 8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset (Machine Learning Mastery)
Q20: When should you use classification over regression?
Answer: Classification produces discrete values and dataset to strict categories, while regression gives you continuous results that allow you to better distinguish differences between individual points. You would use classification over regression if you wanted your results to reflect the belongingness of data points in your dataset to certain explicit categories (ex: If you wanted to know whether a name was male or female rather than just how correlated they were with male and female names.)
More reading: Regression vs Classification (Math StackExchange)
Q21: Name an example where ensemble techniques might be useful.
Answer: Ensemble techniques use a combination of learning algorithms to optimize better predictive performance. They typically reduce overfitting in models and make the model more robust (unlikely to be influenced by small changes in the training data).
You could list some examples of ensemble methods (bagging, boosting, the “bucket of models” method) and demonstrate how they could increase predictive power.
More reading: Ensemble learning (Wikipedia)
Q22: How do you ensure you’re not overfitting with a model?
Answer: This is a simple restatement of a fundamental problem in machine learning: the possibility of overfitting training data and carrying the noise of that data through to the test set, thereby providing inaccurate generalizations.
There are three main methods to avoid overfitting:
- Keep the model simpler: reduce variance by taking into account fewer variables and parameters, thereby removing some of the noise in the training data.
- Use cross-validation techniques such as k-folds cross-validation.
- Use regularization techniques such as LASSO that penalize certain model parameters if they’re likely to cause overfitting.
More reading: How can I avoid overfitting? (Quora)
Q23: What evaluation approaches would you work to gauge the effectiveness of a machine learning model?
Answer: You would first split the dataset into training and test sets, or perhaps use cross-validation techniques to further segment the dataset into composite sets of training and test sets within the data. You should then implement a choice selection of performance metrics: here is a fairly comprehensive list. You could use measures such as the F1 score, the accuracy, and the confusion matrix. What’s important here is to demonstrate that you understand the nuances of how a model is measured and how to choose the right performance measures for the right situations.
More reading: How to Evaluate Machine Learning Algorithms (Machine Learning Mastery)
Q24: How would you evaluate a logistic regression model?
Answer: A subsection of the question above. You have to demonstrate an understanding of what the typical goals of a logistic regression are (classification, prediction, etc.) and bring up a few examples and use cases.
More reading: Evaluating a logistic regression (CrossValidated)
More reading: How a Machine Learning Algorithm Helped Make Hurricane Damage Assessments Safer, Cheaper, and More Effective
Q25: What’s the “kernel trick” and how is it useful?
Answer: The Kernel trick involves kernel functions that can enable in higher-dimension spaces without explicitly calculating the coordinates of points within that dimension: instead, kernel functions compute the inner products between the images of all pairs of data in a feature space. This allows them the very useful attribute of calculating the coordinates of higher dimensions while being computationally cheaper than the explicit calculation of said coordinates. Many algorithms can be expressed in terms of inner products. Using the kernel trick enables us effectively run algorithms in a high-dimensional space with lower-dimensional data.
More reading: Kernel method (Wikipedia)
Machine Learning Interview Questions: Programming
These machine learning interview questions test your knowledge of programming principles you need to implement machine learning principles in practice. Machine learning interview questions tend to be technical questions that test your logic and programming skills: this section focuses more on the latter.
Q26: How do you handle missing or corrupted data in a dataset?
Answer: You could find missing/corrupted data in a dataset and either drop those rows or columns, or decide to replace them with another value.
In Pandas, there are two very useful methods: isnull() and dropna() that will help you find columns of data with missing or corrupted data and drop those values. If you want to fill the invalid values with a placeholder value (for example, 0), you could use the fillna() method.
More reading: Handling missing data (O’Reilly)
Q27: Do you have experience with Spark or big data tools for machine learning?
Answer: You’ll want to get familiar with the meaning of big data for different companies and the different tools they’ll want. Spark is the big data tool most in demand now, able to handle immense datasets with speed. Be honest if you don’t have experience with the tools demanded, but also take a look at job descriptions and see what tools pop up: you’ll want to invest in familiarizing yourself with them.
More reading: 50 Top Open Source Tools for Big Data (Datamation)
Q28: Pick an algorithm. Write the pseudo-code for a parallel implementation.
Answer: This kind of question demonstrates your ability to think in parallelism and how you could handle concurrency in programming implementations dealing with big data. Take a look at pseudocode frameworks such as Peril-L and visualization tools such as Web Sequence Diagrams to help you demonstrate your ability to write code that reflects parallelism.
More reading: Writing pseudocode for parallel programming (Stack Overflow)
Q29: What are some differences between a linked list and an array?
Answer: An array is an ordered collection of objects. A linked list is a series of objects with pointers that direct how to process them sequentially. An array assumes that every element has the same size, unlike the linked list. A linked list can more easily grow organically: an array has to be pre-defined or re-defined for organic growth. Shuffling a linked list involves changing which points direct where—meanwhile, shuffling an array is more complex and takes more memory.
More reading: Array versus linked list (Stack Overflow)
Q30: Describe a hash table.
Answer: A hash table is a data structure that produces an associative array. A key is mapped to certain values through the use of a hash function. They are often used for tasks such as database indexing.
More reading: Hash table (Wikipedia)
Q31: Which data visualization libraries do you use? What are your thoughts on the best data visualization tools?
Answer: What’s important here is to define your views on how to properly visualize data and your personal preferences when it comes to tools. Popular tools include R’s ggplot, Python’s seaborn and matplotlib, and tools such as Plot.ly and Tableau.
More reading: 31 Free Data Visualization Tools (Springboard)
Related: 20 Python Interview Questions
Q32: Given two strings, A and B, of the same length n, find whether it is possible to cut both strings at a common point such that the first part of A and the second part of B form a palindrome.
Answer: You’ll often get standard algorithms and data structures questions as part of your interview process as a machine learning engineer that might feel akin to a software engineering interview. In this case, this comes from Google’s interview process. There are multiple ways to check for palindromes—one way of doing so if you’re using a programming language such as Python is to reverse the string and check to see if it still equals the original string, for example. The thing to look out for here is the category of questions you can expect, which will be akin to software engineering questions that drill down to your knowledge of algorithms and data structures. Make sure that you’re totally comfortable with the language of your choice to express that logic.
More reading: Glassdoor ML interview questions
Q33: How are primary and foreign keys related in SQL?
Answer: Most machine learning engineers are going to have to be conversant with a lot of different data formats. SQL is still one of the key ones used. Your ability to understand how to manipulate SQL databases will be something you’ll most likely need to demonstrate. In this example, you can talk about how foreign keys allow you to match up and join tables together on the primary key of the corresponding table—but just as useful is to talk through how you would think about setting up SQL tables and querying them.
More reading: What is the difference between a primary and foreign key in SQL? and 105 SQL interview questions
Q34: How does XML and CSVs compare in terms of size?
Answer: In practice, XML is much more verbose than CSVs are and takes up a lot more space. CSVs use some separators to categorize and organize data into neat columns. XML uses tags to delineate a tree-like structure for key-value pairs. You’ll often get XML back as a way to semi-structure data from APIs or HTTP responses. In practice, you’ll want to ingest XML data and try to process it into a usable CSV. This sort of question tests your familiarity with data wrangling sometimes messy data formats.
More reading: How Can XML Be Used?
Q35: What are the data types supported by JSON?
Answer: This tests your knowledge of JSON, another popular file format that wraps with JavaScript. There are six basic JSON datatypes you can manipulate: strings, numbers, objects, arrays, booleans, and null values.
More reading: JSON datatypes
Q36: How would you build a data pipeline?
Answer: Data pipelines are the bread and butter of machine learning engineers, who take data science models and find ways to automate and scale them. Make sure you’re familiar with the tools to build data pipelines (such as Apache Airflow) and the platforms where you can host models and pipelines (such as Google Cloud or AWS or Azure). Explain the steps required in a functioning data pipeline and talk through your actual experience building and scaling them in production.
More reading: 10 Minutes to Building A Machine Learning Pipeline With Apache Airflow
Machine Learning Interview Questions: Company/Industry Specific
These machine learning interview questions deal with how to implement your general machine learning knowledge to a specific company’s requirements. You’ll be asked to create case studies and extend your knowledge of the company and industry you’re applying for with your machine learning skills.
Q37: What do you think is the most valuable data in our business?
Answer: This question or questions like it really try to test you on two dimensions. The first is your knowledge of the business and the industry itself, as well as your understanding of the business model. The second is whether you can pick how correlated data is to business outcomes in general, and then how you apply that thinking to your context about the company. You’ll want to research the business model and ask good questions to your recruiter—and start thinking about what business problems they probably want to solve most with their data.
Q38: How would you implement a recommendation system for our company’s users?
Answer: A lot of machine learning interview questions of this type will involve the implementation of machine learning models to a company’s problems. You’ll have to research the company and its industry in-depth, especially the revenue drivers the company has, and the types of users the company takes on in the context of the industry it’s in.
More reading: How to Implement A Recommendation System? (Stack Overflow)
Q39: How can we use your machine learning skills to generate revenue?
Answer: This is a tricky question. The ideal answer would demonstrate knowledge of what drives the business and how your skills could relate. For example, if you were interviewing for music-streaming startup Spotify, you could remark that your skills at developing a better recommendation model would increase user retention, which would then increase revenue in the long run.
The startup metrics Slideshare linked above will help you understand exactly what performance indicators are important for startups and tech companies as they think about revenue and growth.
More reading: Startup Metrics for Startups (500 Startups)
Q40: What do you think of our current data process?

Answer: This kind of question requires you to listen carefully and impart feedback in a manner that is constructive and insightful. Your interviewer is trying to gauge if you’d be a valuable member of their team and whether you grasp the nuances of why certain things are set the way they are in the company’s data process based on company or industry-specific conditions. They’re trying to see if you can be an intellectual peer. Act accordingly.
Machine Learning Interview Questions: General Machine Learning Interest
This series of machine learning interview questions attempt to gauge your passion and interest in machine learning. The right answers will serve as a testament to your commitment to being a lifelong learner in machine learning.
Q41: What are the last machine learning papers you’ve read?
Answer: Keeping up with the latest scientific literature on machine learning is a must if you want to demonstrate an interest in a machine learning position. This overview of deep learning in Nature by the scions of deep learning themselves (from Hinton to Bengio to LeCun) can be a good reference paper and an overview of what’s happening in deep learning — and the kind of paper you might want to cite.
More reading: What are some of the best research papers/books for machine learning?
Q42: Do you have research experience in machine learning?
Answer: Related to the last point, most organizations hiring for machine learning positions will look for your formal experience in the field. Research papers, co-authored or supervised by leaders in the field, can make the difference between you being hired and not. Make sure you have a summary of your research experience and papers ready—and an explanation for your background and lack of formal research experience if you don’t.
Q43: What are your favorite use cases of machine learning models?
Answer: The Quora thread below contains some examples, such as decision trees that categorize people into different tiers of intelligence based on IQ scores. Make sure that you have a few examples in mind and describe what resonated with you. It’s important that you demonstrate an interest in how machine learning is implemented.
More reading: What are the typical use cases for different machine learning algorithms? (Quora)
Q44: How would you approach the “Netflix Prize” competition?
Answer: The Netflix Prize was a famed competition where Netflix offered $1,000,000 for a better collaborative filtering algorithm. The team that won called BellKor had a 10% improvement and used an ensemble of different methods to win. Some familiarity with the case and its solution will help demonstrate you’ve paid attention to machine learning for a while.
More reading: Netflix Prize (Wikipedia)
Q45: Where do you usually source datasets?
Answer: Machine learning interview questions like these try to get at the heart of your machine learning interest. Somebody who is truly passionate about machine learning will have gone off and done side projects on their own, and have a good idea of what great datasets are out there. If you’re missing any, check out Quandl for economic and financial data, and Kaggle’s Datasets collection for another great list.
More reading: 19 Free Public Data Sets For Your First Data Science Project (Springboard)
Q46: How do you think Google is training data for self-driving cars?
Answer: Machine learning interview questions like this one really test your knowledge of different machine learning methods, and your inventiveness if you don’t know the answer. Google is currently using recaptcha to source labeled data on storefronts and traffic signs. They are also building on training data collected by Sebastian Thrun at GoogleX—some of which was obtained by his grad students driving buggies on desert dunes!
More reading: Waymo Tech
Q47: How would you simulate the approach AlphaGo took to beat Lee Sedol at Go?
Answer: AlphaGo beating Lee Sedol, the best human player at Go, in a best-of-five series was a truly seminal event in the history of machine learning and deep learning. The Nature paper above describes how this was accomplished with “Monte-Carlo tree search with deep neural networks that have been trained by supervised learning, from human expert games, and by reinforcement learning from games of self-play.”
More reading: Mastering the game of Go with deep neural networks and tree search (Nature)
Q48: What are your thoughts on GPT-3 and OpenAI’s model?
Answer: GPT-3 is a new language generation model developed by OpenAI. It was marked as exciting because with very little change in architecture, and a ton more data, GPT-3 could generate what seemed to be human-like conversational pieces, up to and including novel-size works and the ability to create code from natural language. There are many perspectives on GPT-3 throughout the Internet — if it comes up in an interview setting, be prepared to address this topic (and trending topics like it) intelligently to demonstrate that you follow the latest advances in machine learning.
More reading: Language Models are Few-Shot Learners
Q49: What models do you train for fun, and what GPU/hardware do you use?
Answer: Such machine learning interview questions tests whether you’ve worked on machine learning projects outside of a corporate role and whether you understand the basics of how to resource projects and allocate GPU-time efficiently. Expect questions like this to come from hiring managers that are interested in getting a greater sense behind your portfolio, and what you’ve done independently.
More reading: Where to get free GPU cloud hours for machine learning
Q50: What are some of your favorite APIs to explore?
Answer: If you’ve worked with external data sources, it’s likely you’ll have a few favorite APIs that you’ve gone through. You can be thoughtful here about the kinds of experiments and pipelines you’ve run in the past, along with how you think about the APIs you’ve used before.
More reading: Awesome APIs
Q51: How do you think quantum computing will affect machine learning?
Answer: With the recent announcement of more breakthroughs in quantum computing, the question of how this new format and way of thinking through hardware serves as a useful proxy to explain classical computing and machine learning, and some of the hardware nuances that might make some algorithms much easier to do on a quantum machine. Demonstrating some knowledge in this area helps show that you’re interested in machine learning at a much higher level than just implementation details.
Machine learning and data science are driving a technological revolution. As a result, data scientists and machine learning professionals are in high demand.
More reading: Quantum Machine Learning
Companies are no longer just collecting data. They’re seeking to use it to outpace competitors, especially with the rise of AI and advanced analytics techniques. Between organizations and these techniques are the data scientists – the experts who crunch numbers and translate them into actionable strategies. The future, it seems, belongs to those who can decipher the story hidden within the data, making the role of data scientists more important than ever.
In this article, we’ll look at 13 careers in data science, analyzing the roles and responsibilities and how to land that specific job in the best way. Whether you’re more drawn out to the creative side or interested in the strategy planning part of data architecture, there’s a niche for you.
Is Data Science A Good Career?
Yes. Besides being a field that comes with competitive salaries, the demand for data scientists continues to increase as they have an enormous impact on their organizations. It’s an interdisciplinary field that keeps the work varied and interesting.
10 Data Science Careers To Consider
Whether you want to change careers or land your first job in the field, here are 13 of the most lucrative data science careers to consider.
Data Scientist
Data scientists represent the foundation of the data science department. At the core of their role is the ability to analyze and interpret complex digital data, such as usage statistics, sales figures, logistics, or market research – all depending on the field they operate in.
They combine their computer science, statistics, and mathematics expertise to process and model data, then interpret the outcomes to create actionable plans for companies.
General Requirements
A data scientist’s career starts with a solid mathematical foundation, whether it’s interpreting the results of an A/B test or optimizing a marketing campaign. Data scientists should have programming expertise (primarily in Python and R) and strong data manipulation skills.
Although a university degree is not always required beyond their on-the-job experience, data scientists need a bunch of data science courses and certifications that demonstrate their expertise and willingness to learn.
Average Salary
The average salary of a data scientist in the US is $156,363 per year.
Data Analyst
A data analyst explores the nitty-gritty of data to uncover patterns, trends, and insights that are not always immediately apparent. They collect, process, and perform statistical analysis on large datasets and translate numbers and data to inform business decisions.
A typical day in their life can involve using tools like Excel or SQL and more advanced reporting tools like Power BI or Tableau to create dashboards and reports or visualize data for stakeholders. With that in mind, they have a unique skill set that allows them to act as a bridge between an organization’s technical and business sides.
General Requirements
To become a data analyst, you should have basic programming skills and proficiency in several data analysis tools. A lot of data analysts turn to specialized courses or data science bootcamps to acquire these skills.
For example, Coursera offers courses like Google’s Data Analytics Professional Certificate or IBM’s Data Analyst Professional Certificate, which are well-regarded in the industry. A bachelor’s degree in fields like computer science, statistics, or economics is standard, but many data analysts also come from diverse backgrounds like business, finance, or even social sciences.
Average Salary
The average base salary of a data analyst is $76,892 per year.
Business Analyst
Business analysts often have an essential role in an organization, driving change and improvement. That’s because their main role is to understand business challenges and needs and translate them into solutions through data analysis, process improvement, or resource allocation.
A typical day as a business analyst involves conducting market analysis, assessing business processes, or developing strategies to address areas of improvement. They use a variety of tools and methodologies, like SWOT analysis, to evaluate business models and their integration with technology.
General Requirements
Business analysts often have related degrees, such as BAs in Business Administration, Computer Science, or IT. Some roles might require or favor a master’s degree, especially in more complex industries or corporate environments.
Employers also value a business analyst’s knowledge of project management principles like Agile or Scrum and the ability to think critically and make well-informed decisions.
Average Salary
A business analyst can earn an average of $84,435 per year.
Database Administrator
The role of a database administrator is multifaceted. Their responsibilities include managing an organization’s database servers and application tools.
A DBA manages, backs up, and secures the data, making sure the database is available to all the necessary users and is performing correctly. They are also responsible for setting up user accounts and regulating access to the database. DBAs need to stay updated with the latest trends in database management and seek ways to improve database performance and capacity. As such, they collaborate closely with IT and database programmers.
General Requirements
Becoming a database administrator typically requires a solid educational foundation, such as a BA degree in data science-related fields. Nonetheless, it’s not all about the degree because real-world skills matter a lot. Aspiring database administrators should learn database languages, with SQL being the key player. They should also get their hands dirty with popular database systems like Oracle and Microsoft SQL Server.
Average Salary
Database administrators earn an average salary of $77,391 annually.
Data Engineer
Successful data engineers construct and maintain the infrastructure that allows the data to flow seamlessly. Besides understanding data ecosystems on the day-to-day, they build and oversee the pipelines that gather data from various sources so as to make data more accessible for those who need to analyze it (e.g., data analysts).
General Requirements
Data engineering is a role that demands not just technical expertise in tools like SQL, Python, and Hadoop but also a creative problem-solving approach to tackle the complex challenges of managing massive amounts of data efficiently.
Usually, employers look for credentials like university degrees or advanced data science courses and bootcamps.
Average Salary
Data engineers earn a whooping average salary of $125,180 per year.
Database Architect
A database architect’s main responsibility involves designing the entire blueprint of a data management system, much like an architect who sketches the plan for a building. They lay down the groundwork for an efficient and scalable data infrastructure.
Their day-to-day work is a fascinating mix of big-picture thinking and intricate detail management. They decide how to store, consume, integrate, and manage data by different business systems.
General Requirements
If you’re aiming to excel as a database architect but don’t necessarily want to pursue a degree, you could start honing your technical skills. Become proficient in database systems like MySQL or Oracle, and learn data modeling tools like ERwin. Don’t forget programming languages – SQL, Python, or Java.
If you want to take it one step further, pursue a credential like the Certified Data Management Professional (CDMP) or the Data Science Bootcamp by Springboard.
Average Salary
Data architecture is a very lucrative career. A database architect can earn an average of $165,383 per year.
Machine Learning Engineer
A machine learning engineer experiments with various machine learning models and algorithms, fine-tuning them for specific tasks like image recognition, natural language processing, or predictive analytics. Machine learning engineers also collaborate closely with data scientists and analysts to understand the requirements and limitations of data and translate these insights into solutions.
General Requirements
As a rule of thumb, machine learning engineers must be proficient in programming languages like Python or Java, and be familiar with machine learning frameworks like TensorFlow or PyTorch. To successfully pursue this career, you can either choose to undergo a degree or enroll in courses and follow a self-study approach.
Average Salary
Depending heavily on the company’s size, machine learning engineers can earn between $125K and $187K per year, one of the highest-paying AI careers.
Quantitative Analyst
Qualitative analysts are essential for financial institutions, where they apply mathematical and statistical methods to analyze financial markets and assess risks. They are the brains behind complex models that predict market trends, evaluate investment strategies, and assist in making informed financial decisions.
They often deal with derivatives pricing, algorithmic trading, and risk management strategies, requiring a deep understanding of both finance and mathematics.
General Requirements
This data science role demands strong analytical skills, proficiency in mathematics and statistics, and a good grasp of financial theory. It always helps if you come from a finance-related background.
Average Salary
A quantitative analyst earns an average of $173,307 per year.
Data Mining Specialist
A data mining specialist uses their statistics and machine learning expertise to reveal patterns and insights that can solve problems. They swift through huge amounts of data, applying algorithms and data mining techniques to identify correlations and anomalies. In addition to these, data mining specialists are also essential for organizations to predict future trends and behaviors.
General Requirements
If you want to land a career in data mining, you should possess a degree or have a solid background in computer science, statistics, or a related field.
Average Salary
Data mining specialists earn $109,023 per year.
Data Visualisation Engineer
Data visualisation engineers specialize in transforming data into visually appealing graphical representations, much like a data storyteller. A big part of their day involves working with data analysts and business teams to understand the data’s context.
General Requirements
Data visualization engineers need a strong foundation in data analysis and be proficient in programming languages often used in data visualization, such as JavaScript, Python, or R. A valuable addition to their already-existing experience is a bit of expertise in design principles to allow them to create visualizations.
Average Salary
The average annual pay of a data visualization engineer is $103,031.
Resources To Find Data Science Jobs
The key to finding a good data science job is knowing where to look without procrastinating. To make sure you leverage the right platforms, read on.
Job Boards
When hunting for data science jobs, both niche job boards and general ones can be treasure troves of opportunity.
Niche boards are created specifically for data science and related fields, offering listings that cut through the noise of broader job markets. Meanwhile, general job boards can have hidden gems and opportunities.
Online Communities
Spend time on platforms like Slack, Discord, GitHub, or IndieHackers, as they are a space to share knowledge, collaborate on projects, and find job openings posted by community members.
Network And LinkedIn
Don’t forget about socials like LinkedIn or Twitter. The LinkedIn Jobs section, in particular, is a useful resource, offering a wide range of opportunities and the ability to directly reach out to hiring managers or apply for positions. Just make sure not to apply through the “Easy Apply” options, as you’ll be competing with thousands of applicants who bring nothing unique to the table.
FAQs about Data Science Careers
We answer your most frequently asked questions.
Do I Need A Degree For Data Science?
A degree is not a set-in-stone requirement to become a data scientist. It’s true many data scientists hold a BA’s or MA’s degree, but these just provide foundational knowledge. It’s up to you to pursue further education through courses or bootcamps or work on projects that enhance your expertise. What matters most is your ability to demonstrate proficiency in data science concepts and tools.
Does Data Science Need Coding?
Yes. Coding is essential for data manipulation and analysis, especially knowledge of programming languages like Python and R.
Is Data Science A Lot Of Math?
It depends on the career you want to pursue. Data science involves quite a lot of math, particularly in areas like statistics, probability, and linear algebra.
What Skills Do You Need To Land an Entry-Level Data Science Position?
To land an entry-level job in data science, you should be proficient in several areas. As mentioned above, knowledge of programming languages is essential, and you should also have a good understanding of statistical analysis and machine learning. Soft skills are equally valuable, so make sure you’re acing problem-solving, critical thinking, and effective communication.
Since you’re here…Are you interested in this career track? Investigate with our free guide to what a data professional actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp which will help you land a job or your tuition back!
This post was originally published in 2017. It has been updated to include more current information.


