![Data Structures and Algorithms Interview Questions [2022 Prep Guide]](https://www.springboard.com/blog/wp-content/uploads/2020/07/data-structures-and-algorithms-interview-questions-2022-prep-guide.jpg)
Algorithms and data structures are foundational to computer science. As the scaffolding for programming languages, tech recruiters place an emphasis on algorithms and data structures in interviews.
If you’re looking for help with interview questions in those areas, you’ve come to the right place. We’re going to cover all the data structure and algorithms interview questions that you should prepare for in 2022.
Entry-Level Data Structure Interview Questions
What Is a Data Structure?
A data structure is a format for storing data on a computer so that it can be accessed and modified easily.
What Are the Different Types of Data Structures?
The different types of data structures are:
- Arrays: A collection of data values stored sequentially
- Stacks: Last-in-first-out (LIFO) data structures where the element placed last is accessed first.
- Queues: A first-in-first-out data structure.
- Linked lists: A collection of data values stored in a linear order and connected to each other
- Graphs: A data structure in which data values are placed in nodes connected by edges
- Trees: Similar to a linked list, but with data values linked in a hierarchical fashion
- Heaps: A binary tree data structure wherein parent data values can be compared to child data values
- Hash table: A table where each value is assigned a key and then stored, making accessing individual values easy.
What Are the Benefits of Learning Data Structures?
Studying data structures is a way to tap into the power of data. Without data structures, you’d have a large amount of data that you couldn’t easily access. When you use data structures, you can retrieve and manipulate data to unearth insights.
What Are the Applications of Data Structures?
Data structures can be used to:
- Implement dynamic memory allocation
- Model sets and other collections of data
- Search through large data sets easily
- Modeling networks
- Solving shortest problems
What Is the Difference Between File Structure and Storage Structure?

A storage structure is a data structure in the computer’s memory. A file system is also a representation of a data structure, but in the auxiliary memory of a computer.
Linear Data Structures vs Non-Linear Data Structures: What Is the Difference?
A linear data structure stores data in a linear sequence. You can only traverse the data structure in that linear sequence. Arrays and stacks are examples of linear data structures.
Non-linear data structures arrange data in ways that are not linear. A graph, for example, has nodes which are connected to each other through edges. The relationships between the data values are defined by which nodes are connected through edges, and not by a sequential arrangement. Trees are also non-linear data structures.
What Is an Array?
An array is a data structure in which data values are stored in contiguous locations in the memory. Every element is given an index, which is its position in the sequence of data values.
How Can You Store the Elements of a 2D Array in the Memory?
There are two techniques used to store 2D arrays:
- Row-major ordering
All of the rows of the array are stored contiguously in this technique. You start with the first row, then move on to the second, and so forth, until the entire array has been stored in the memory.
- Column-major ordering
Under this technique, the columns of the array are stored contiguously instead of the rows. You start with the first column and move on to the subsequent ones sequentially.
What Is a Linked List?
A linked list is a linear data structure, but with data values that are not stored in contiguous memory locations. So in order to traverse the list, each element of the list is connected to the next one using a pointer.
Explain Multidimensional Arrays.
The standard array has only one dimension; data values are arranged linearly. But imagine that you want to transfer elements in a tabular format into an array. Tables have two dimensions, so you would need a two-dimensional array to describe it.
Any array that has more than one dimension is a multidimensional array. A 2D array is the most basic form of a multidimensional array.
Are Linked Lists Considered Linear or Non-Linear Data Structures?
Linked lists are linear data structures.
How Can You Use Linked Lists and Arrays? Give Examples.
A linked list is a linear data structure where data values are not stored in contiguous memory locations. Image viewer applications can use linked lists to let users go from one image to the next in chronological order. These images don’t need to be stored in contiguous locations, but each one needs to point to the next so that users can scroll through the album.
Arrays are simple data structures which store the same types of data values in contiguous locations. Imagine you want to run every day and store your daily distance in a data structure. In that case, you could use an array to store the distance for each day and access previous entries easily.
Do Linked Lists Have Any Advantages Over Arrays?
Yes, linked lists have a few advantages in comparison with arrays.
- Linked lists offer dynamic storage capacity and can easily accommodate newer values. Arrays are initialized with a particular size and can’t adapt to memory requirements as a result.
- It is easier to insert or delete elements in a linked list since the elements are not stored in contiguous memory locations.
How Do You Reference All of the Elements in a One-Dimension Array?
An indexed loop can be used to reference all of the items in a one-dimensional array. The loop would start at the first array location and cycle through all of them one by one. Let’s say there are n elements in an array. In that case, the loop would go from 0 through n.
What Are Dynamic Data Structures?

Dynamic data structures are data structures whose size is not fixed. They are an important utility for programmers because, in most situations, you will not know exactly how much memory a particular data structure requires. In that situation, dynamic data structures can be used to add or remove new elements easily.
Why Is Algorithm Analysis Important?
Algorithm analysis is the process of assessing the computational capabilities of a particular algorithm and determining whether it can serve a particular use case. This is important to do before any programming project because it prevents unforeseen challenges and gives programmers an idea of what they can achieve with a particular algorithm.
Explain Doubly-Linked Lists (DLL).
A doubly linked list is a modification of a linked list in which every element points to both the element before it and the element after it. It is easy to navigate a doubly linked list both forwards and backwards for this reason.
Every entry in a doubly linked list has the following:
- A data field to carry a particular data value
- A link to the previous entry in the list
- A link to the next entry in the list
What Are the Applications of Doubly Linked Lists?
Any application where you require quick forward and backward navigation can employ doubly linked lists. Some examples include:
- The actions that you’ve taken in an image editing app can be stored in a doubly linked list to allow for each undo/redo operation.
- More complex data structures like binary trees and hash tables can be constructed using doubly linked lists.
- Search engine results pages can be linked to each other using doubly linked lists.
Explain Stack Along With Its Applications.
A stack is a data structure in which elements are placed one on top of the other and additions and deletions can occur only at the top. Stacks can be used in the following applications:
- A stack can be used in applications where users are enabled to backtrack on previous operations by one step or move forward with a new operation.
- Converting infix expressions into postfix expressions.
- The process of reversing the characters in a string can be completed by placing them in a stack and using the pop operation.
Define Postfix Expression.
A postfix expression is a format for arranging operators and operands in which the operators are always placed after the operands. The following is an example of a postfix expression:
ab+cd-*
The infix version of this expression is:
(a+b)*(c-d)
Senior-Level Data Structure Interview Questions
What Do You Mean by Queue? Can You Explain Its Applications?
A queue is a data structure which follows the First In First Out (FIFO) logic for operations, which means that the first element input into the queue is operated on first.
A scheduling system is a good example of an application of a queue. Imagine a computing environment where CPU resources are being shared by multiple people. In that case, the work that they want to do can be placed in a queue, with the commands that came first being executed by the queue first.
What Is a Dequeue?

Dequeuing is an operation that can be performed on a queue in which an element at the very front of the queue is removed or accessed for an operation.
Are Stack and Queue the Same Thing? If Not, Explain Why.
Stacks and queues are different data structures. The key differences between them are:
- Stacks follow a first-in-first-out logic whereas queues employ a last-in-first-out logic.
- You can insert and delete elements only at the top of a stack. On the other hand, elements are added at one end of a queue and deleted at the other.
- Stacks use only one pointer, which is for the top of the stack. Queues need two pointers to address the front of the queue and back of the queue.
- Stacks are mainly used in problems requiring recursion whereas queues are better used in applications that require sequential processing.
What Is the Process Behind Storing Variables in Memory?
The simplest way to store anything in the computer’s memory is using a variable. A variable represents one piece of data, such as a character or a number. Variables make it easier to write programmes because you can refer to values by their names and write generic programs or functions that work with any value.
The way variables are stored depends on the programming language being used. Some programming languages require declaring variables and others don’t. There are certain programming languages in which variables can only be of a certain type while others are more flexible.
How To Implement a Queue Using a Stack?
You can implement a queue using a stack by making either the enqueue or dequeue operation costly. In each example below, we will assume two stacks, s1 and s2. The s1 stack holds the data that we are working with while s2 is for temporary data storage.
Enqueue Method
Step 1: If s1 is empty, then push the first element of the stack into s1.
Step 2: If s1 is not empty, then push elements one by one into s2. Now take the first element and place it in s1, then take all the elements in s2 and place it back in s1.
We’ve thus ensured that the first element is always on top and all of the other elements follow it.
Dequeue Method
You can implement a queue using stacks by making the dequeue operation costly in the following way:
Step 1: If s1 is empty, then don’t execute any operation on the data. Simply return an error message saying that the stack is empty.
Step 2: If s1 is not empty, then take all the elements in that stack and place them in s2 one by one. Remove the first element in s2 and move all the elements in s2 into s1.
By moving all the elements in s1 into s2, we’ve managed to reverse the order of the data values. Now that the first element in the queue is at the top of s2, we can use the pop function to remove it.
How Can You Implement a Stack Using Queues?
You can implement a stack using queues either by making the push or pop operations costly. Here are the algorithms for both methods.
Making the Push Operation Costly
We use two queues (q1 and q2) to implement a stack by making the push operation costly.
- We start by moving all the elements from q1 to q2
- Next, enqueue the new element into q1
- Transfer all the elements in q2 back into q1
Making the Pop Operation Costly
- Move all elements except the last element from q1 to q2
- Remove the last element that remains in q1
- Move all the elements from q2 back into q1
What Is the Difference Between Push and Pop Operations?
Push and pop are operations that are conducted on stacks. A push operation adds an element into a stack. On the other hand, pop operations remove elements from the stack.
Which Sorting Algorithm Is Considered the Fastest?

Quicksort is generally considered the fastest sorting algorithm. It has a best case time complexity of O(n log n) and its time complexity in the worst case is O(n^2). However, it is considered the fastest sorting algorithm because it has an average case time complexity of O(n logn), which is faster than other algorithms.
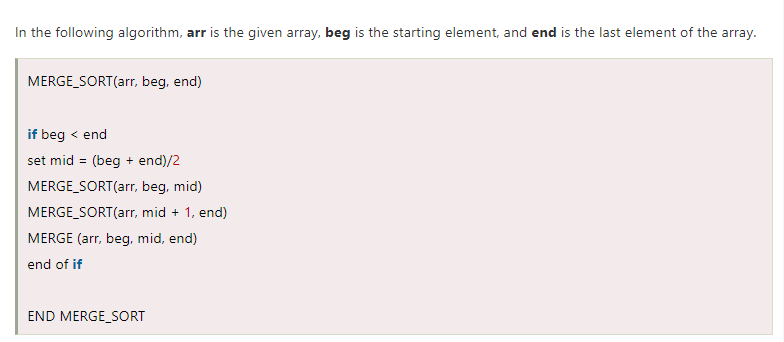
What Is Merge Sort and How Is It Implemented?
Merge sort belongs to a class of sorting algorithms known as divide and conquer approaches. It divides a list of elements into two halves and then recursively applies the merge sort technique on each half, and then merges the two after sorting them individually.
The following is the algorithm for a merge sort.
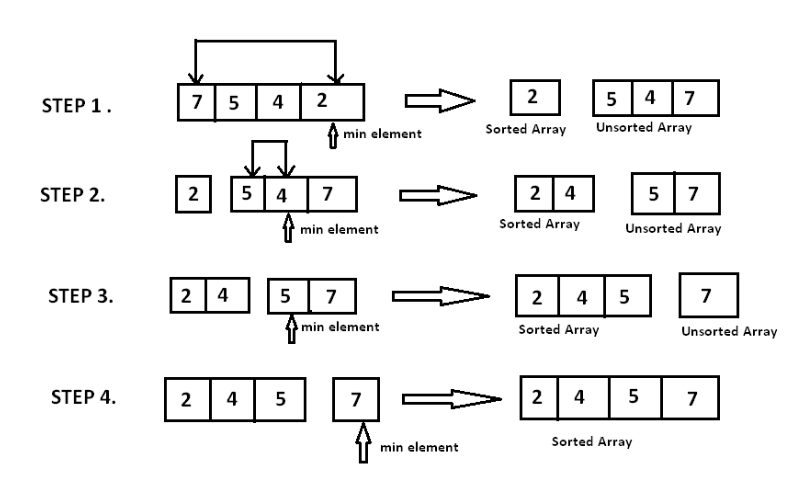
Can You Explain the Working of a Selection Sort?
Selection sort follows a simple process to sort a list of elements. To start, the list is divided into two parts. The part on the left is sorted and the part on the right is unsorted. Initially, the list is unsorted so only the first element is on the left.
We then scan the array and find the smallest element. That element is swapped with the first element and becomes part of the sorted array. We then repeat this process with the second element and so on. The following image depicts the process.
Define an Asymptotic Analysis of an Algorithm.
An asymptotic analysis determines the mathematical run-time performance of different algorithms. Through asymptotic analysis, we are able to establish the best case, worst case, and average case scenarios for algorithms.
Explain Asymptotic Notations.
The following notations are used in the asymptotic analysis of algorithms.
Big Oh Notation
The big oh notation, O(n), describes the upper bound for the runtime of an algorithm. It thus describes the worst case time complexity of an algorithm.
Omega Notation
This is the lower bound, or the best case scenario, for an algorithm’s running time.
Theta Notation
The theta notation combines both the upper and lower bound running time of an algorithm.
What Is a Hash Table in Data Structures?
A hash table is a data structure in which data is stored along with an index, which is where the element is stored in the memory. This makes hash tables a lot like arrays, except the data values are stored along with information on their location in the memory.
Can You Use an Object as a Key in HashMap?
Yes, you can use an object as a key in a HashMap.
Can You Store a Duplicate Key in HashMap?
You cannot store a duplicate key in a HashMap.
How Do Hashmaps Handle Collisions in Java?
Hashmaps handle collisions in Java by using a linked list to record entries that have been placed in the same array location. But from Java 8 onwards, the switch was made to using balanced trees for the same purpose instead of linked lists.
What Is the Time Complexity of Basic Operations Get() and Put() in Hashmap Class?
The get and put operations have a time complexity of O(1) in Hashmaps assuming that the key-value pairs are evenly distributed across the array or buckets.
Explain the Implementation of LRU Cache Using Data Structures.

Two data structures are used to implement an LRU cache. The first is a queue, which is implemented using a linked list. The other is a hash, which holds the page number as a key and the value of the hash is the address of the corresponding queue node.
If a particular page is referenced and is available in the memory, then the node of the list is detached and is placed at the head of the queue. If a particular page is requested and is not in the memory, then it is brought into the memory.
There are situations in which the queue becomes full, in which case we remove a node from the back of the queue and add a new one in front.
Get To Know Other Software Engineering Students

Abdelkareem ElSharief
Software Engineer at Bread

Jack Mayer
Software Engineer at Whitepages

Oscar Herrera
Student In The Software Engineering Bootcamp at Springboard
Define a Tree Data Structure.
A tree is a hierarchical data structure in which a central node branches into sub nodes. Each sub node can have its own lead nodes.
What Are Binary Trees?
A binary tree is a kind of tree implementation in which each node can have, at most, two sub nodes or children. The two children are referred to as the left child and right child.
Write a Recursive Function To Calculate the Height of a Binary Tree in Java.
To find the height of a binary tree, we traverse its length in a postorder sequence. We then calculate the height of the left and right subtrees, which we can combine to determine the height of the entire binary tree. The following Java code can be used to achieve that.
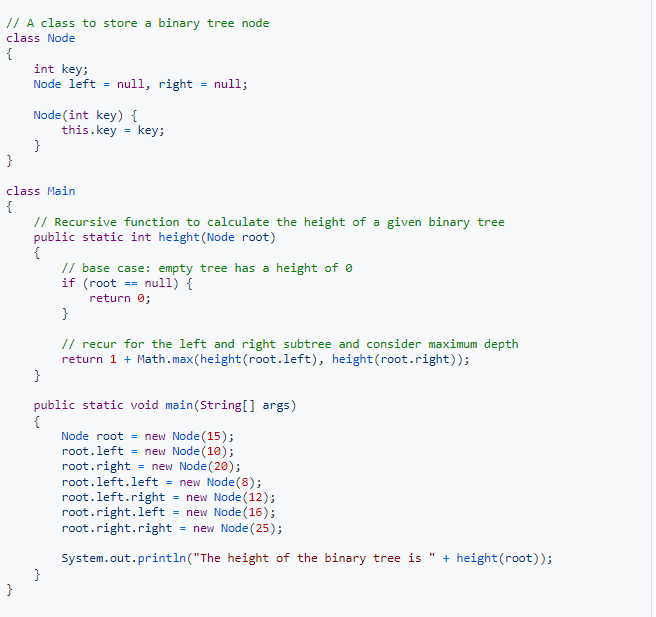
What Is the Maximum Number of Nodes in a Binary Tree of Height K?
The maximum number of nodes in a binary tree of height k is 2k-1, where k is greater than or equal to 1.
Describe the Different Kinds of Tree Traversals for a Binary Search Tree.
There are three ways to traverse a tree. They are:
Inorder Traversal
Traverse the tree starting at the left subtree, then to the root of the tree, and finishing off at the right subtree.
Preorder Traversal
Preorder traversal starts at the root, then moves to the left subtree and finally the right subtree.
Postorder Traversal
This involves covering the tree starting from the left subtree and moving to the right subtree. You then move from the right subtree to the root to complete the traversal.
What Is a Binary Search Tree?
A binary search tree is a special tree implementation in which internal nodes store keys greater than the keys in the left subtrees and less than the keys in the right subtrees.
Is Binary Search Better Than Linear Search?
Yes, binary search is more efficient than linear search. It has a time complexity of O(log n) whereas the time complexity of linear search is O(n).
Define an AVL Tree.
An AVL tree is a binary search tree whose height is self-balancing. This is achieved by designing it so that the difference in the height of the left subtree and right subtree can never exceed one for any node.
Explain Graph Data Structures.
A graph is a data structure in which a set of nodes is connected to some or all of the other nodes via edges. As a result, graphs are non-linear data structures.
What Are the Applications of Graph Data Structures?
Graphs can be used in many different scenarios. That includes:
- In map applications, where the intersection of two roads is designated as a node
- Social media applications conceptualize networks of users by assigning each user as a node and their friends as the nodes that they are connected to.
- The Internet can be visualized in terms of a graph, where each page that links to another page has an edge that connects to it in the graph.
How Do You Represent a Graph?
The two most common ways of representing graphs is by using adjacency lists and adjacency matrices.
An adjacency matrix is a two-dimensional array where each row and column represents a particular vertex of the graph. If there exists an edge between any two vertices, then the corresponding entry in the array is designated by a 1. If not, it is designated by a 0.
Adjacency lists represent graphs in the form of an array of linked lists. As you can see in the image below, each node in the graph becomes an index element in a linked list. And each index element is connected to the same nodes as in the graph, but this time in a linked list.
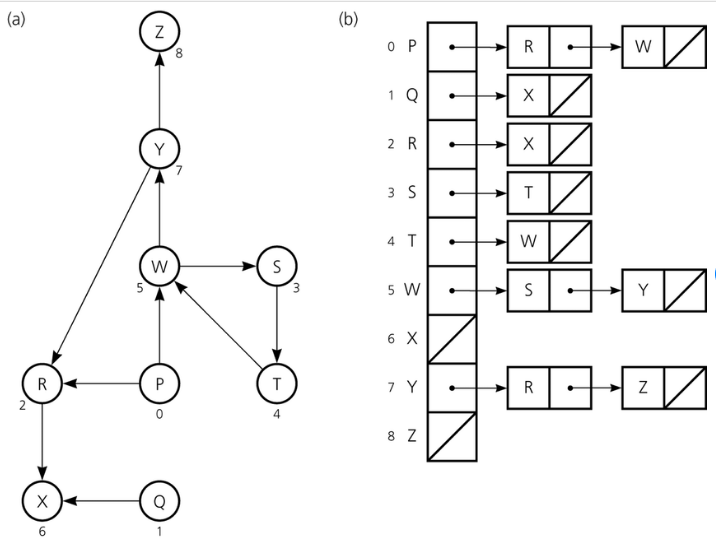
How Do You Differentiate Between a Tree and Graph Data Structure?
The following are the key differences between trees and graphs:
- Trees have a root node from which all other nodes originate. Graphs don’t have root nodes.
- The vertices in a graph can have bidirectional connections. There is only a single path between two vertices in a tree.
- The nodes in a graph can connect to themselves, which is not possible in a tree.
- Trees are a hierarchical data structure whereas graphs are flat networks.
Can You Differentiate Between a B Tree and B+ Tree?
The following are the differences between B trees and B+ trees:
- Both the internal and leaf nodes in a B tree have pointers. Only the leaf nodes in a B+ tree have pointers.
- Searching a B+ tree is faster because the keys are always in the leaf nodes. The keys of a B tree are not necessarily in the leaf node and searching takes more time as a result.
- B trees don’t maintain a duplicate of the keys in the tree. B+ trees maintain duplicates of keys.
- The lead nodes of B+ trees are stored in the form of structural linked lists. This is not the case for B trees.
What Is the Difference Between the Breadth-First Search (BFS) and Depth-First Search (DFS)?
Breadth-first search uses the queue data structure to find the shortest path in a graph. Depth-first search does the same thing but using the stack data structure.
How Do You Know When To Use DFS Over BFS?
The search methodology you use will depend on the depth of the node you’re searching. If the node is shallow, then you should use BFS. But if there are a lot of edges between the source and the node to which the search is being conducted, then you should use DFS.
What Is Topological Sorting in a Graph?
Topological sorting is a way of ordering the vertices in a graph. The vertices are ordered in such a way that if there is an edge from vertex v1 to vertex v2, then v1 is placed before v2 in the topological sorting order.
What Is a Heap Data Structure?
A heap is a data structure that is based on trees. Heaps are constructed in such a way that they are complete binary trees, which means that all the levels are filled and every node is left-justified.
What Is the Advantage of a Heap Over a Stack?
Heaps allocate memory dynamically, which is why they’re more flexible than stacks. You don’t need to initialize heaps with a particular memory size. With a heap, you can add elements on the go, and the heap will adapt to the new storage requirements.
Can Dynamic Memory Allocation Help in Managing Data?
Yes, dynamic memory allocation can help in managing data. It is easier to work with data when it can be assigned to memory locations dynamically.
What Is a Jagged Array?
A jagged array is an array of arrays, which means that it is an array that contains other arrays. The arrays within a jagged array can be of varying lengths.
What Is the Difference Between Null and Void?
When a variable is assigned as null, that means that it is an empty value. A void pointer, on the other hand, is a pointer that doesn’t have any size initially.
What Is the Left View of a Binary Tree?
The left view of a binary tree is all the nodes that you visit when you traverse the tree from its left side.
Data Structures and Algorithms Interview Questions for Python Users
What Is the Difference Between a List and a Tuple [In Python]?
![What Is the Difference Between a List and a Tuple [In Python]?](https://www.springboard.com/blog/wp-content/uploads/2022/03/what-is-the-difference-between-a-list-and-a-tuple-in-python.jpg)
In short, lists are mutable (they can be modified) while tuples are immutable (they cannot be modified). Lists are ordered by one central index, while a tuple may hold multiple data types together in an index-like form.
Are Dictionaries or Lists Faster for Lookups?
This question tests your grasp of the implications for Python data structures and the algorithms you can implement on top of them. Lists are slower for lookups: it’ll take O(N) time since filtering through for a value will require as a worst-case scenario filtering through every value in the list. Dictionaries are well-set up with key-value pairs, similar to a hash table. Thus the time to search will be O(1) as long as you have the correct key.
What Are Three Different Ways of Fetching Every Third Item in a List?
There are three different ways to do this: via a yield function, a list comprehension, or a for loop. All three are demonstrated here.
Using List Comprehension, Print the Odd Numbers Between 0 and 100.
List comprehensions are a feature in Python that allows us to work with algorithms within the default list data structure in Python. Here, we’re looking for odd numbers.

A list comprehension allows us to simplify our range and filtering algorithm so we can pack it into one line of code. This piece of code returns every element between 0 and 100 if it is divisible by 2.
You should be prepared to describe the list comprehension in detail and with the right notation.
Write a Regular Expression That Confirms an Email Id Using the Python Reg Expression Module “Re”?
When it comes to Python algorithms, a lot of the work is usually abstracted by the built-in default data structures or easy methods that can be called in one line. Regular expression algorithms, used for filtering through selections of text, are often some of the most difficult to grasp. You’ll have to get familiar with regular expression rules in Python to be able to write out the answer.

Data Structures and Algorithms Interview Questions for JavaScript Users
What Is the Result of “10”+20+30 in JavaScript?
This interview question tests your knowledge of JavaScript data primitives, the data types that can be composed into different data structures in Python. In this case, it’s a mix between string and numbers data types. Knowing that the result will be 102030 rather than 60 means that you understand that when a string type is invoked with the + operator in JavaScript, the automatic behavior is to turn it into a concatenation operator.
Only by ensuring that everything that interacts with the + operator is a number or BigInt data type can you ensure that a desired behavior of addition happens.
What Will Be the Output of the Code Below?

This question tests your knowledge of arrays and how they interact with different data types. In this case, you should understand that the length of the tree array will still be five, even after the delete function. The delete function simply takes the third indexed item (since JavaScript arrays are 0-indexed, this means “maple” or the fourth element) and makes it undefined. The length of the underlying array is still the same, it just contains an undefined element instead of the string “maple”.
How Do You Add an Element at the Beginning of an Array? How Do You Add One at the End?
You have to use the default .push() method to add something at the end of an array, while you can use the default .unshift() method to add something at the beginning. Knowing this answer helps prove that you understand how arrays fundamentally work.
What Is the For-In Loop in JavaScript? Give Its Syntax.
The for-in loop is a fundamental part of iterating through data structures. You should be able to describe its syntax to interviewers without hesitation.

This is the case for-in loop implementation in JavaScript. You would loop through an array by replacing the object name with the array name, and then place the piece of iterative code inside the block.
What Are Arrow Functions?
Arrow functions are a concise and short way to write functions in ES6 and above. They are a way for you to condense your algorithmic logic. The following example describes an arrow function which simply prints “hello” in the JavaScript console.
Data Structures Interview Questions and Answers [General]
Introduce Yourself.
Make this answer short and pointed. Talk about your educational background and your expertise as a developer. Include some information on your passion for computer science and its applications. Refrain from going into your personal background or interests outside of the job you’re applying for, unless you’re explicitly asked to.
What Do You Know About Data Structures?
This is a chance to talk about what data structures are and why they are integral to any scalable computational projects. Explain what makes them important and how they can guide you as a programmer. You can name a few different data structures but there is no need to go too deep into the specifics of each.
Why Did You Opt for a Career in Software Development?
One way to answer this question is to explain how you first got interested in software and describe some of the first programs you wrote. Then talk about some of the personal projects or open source contributions you’ve made to illustrate your interest in the field.
What Is the Most Challenging Project You Encountered on Your Learning Journey?
Be honest when answering this question. Start by describing the project and what you were trying to achieve. Then describe the challenges you faced and your gaps in learning. Finish by explaining how you filled those gaps and completed the project.
Situational Question Based on the Resume.
Here are some questions that might arise based on what’s on your resume.
A common question is whether you can work with a specific programming language despite not having a ton of experience with it. If you’re asked this, reassure recruiters by letting them know that you’re an autodidact, and are open to learning new things on the job. You can give specific examples of when you’ve done that in the past.
Gaps in your resume can also lead to questions from recruiters. If you do have a gap, then explain it honestly. Most companies don’t mind a gap in a resume as long as it’s justified.
Data Structures Interview FAQs
How Do You Prepare for a Software Engineer/Developer Interview?
It’s important to go over the job description and identify what a company is looking for in a software engineer or software developer. Begin your preparations accordingly. For example, if a job description mentions Python and algorithms, then study both of those topics. Start by working on them broadly and then go over the most common interview questions for them.
Is Software Development a Good Career?
Software development can be a great career choice for several reasons. It is a field that is perennially in high demand and relatively lucrative. It also gives you the opportunity to work in many different kinds of industries and roles.
How Should You Answer “Why Should We Hire You as a Software Developer?” During an Interview?
When recruiters ask this question, they’re looking to find out whether you’re a good fit for the company. You need to show that you understand what the company does and what your role will be. Make sure that you research the company and know what it offers. If possible, connect to a developer in the company to learn about they’re work and the culture of the team. Include your findings in your answer and explain why you are the perfect candidate for the job.
Since you’re here…
Were you one of the tens of thousands of workers impacted by this year’s tech layoffs? Springboard wants to help. Our new Career Reboot Scholarship is intended to assist job seekers from tech looking to upskill, reskill and stand out in a competitive hiring environment. Get $1,000 off any Springboard bootcamp in software engineering, data analytics, UX design, cybersecurity, tech sales, and more. Visit this page for eligibility requirements and to apply.


