![How To Become a Data Engineer [2023 Career Guide]](https://www.springboard.com/blog/wp-content/uploads/2020/11/how-to-become-a-data-engineer-2023-career-guide.jpeg)
Though data scientists may garner more headlines than other data professionals, data science isn’t necessarily the most exciting career in the data space. Today, the growing demand for data engineers is actually outpacing the growing demand for data scientists—between 2021 and 2022, there was a 100% increase in available data engineering roles, according to DataCamp.
If you’re looking to cash in on this trend, then you’re in the right place. Below, we’ll tell you everything you need to know about how to become a data engineer, and what to expect once you’re hired.
Ready? Then let’s get started.
What Does a Data Engineer Do?
Data engineers are the town planners of the data world. They are the professionals who come up with the architecture of data systems and build pipelines to channel data through different parts of the system. They may also build relational databases and data warehouses.
Is It Hard To Become a Data Engineer?
Data engineering is a highly technical role. You need to have a strong grasp of computing, data handling, and, in certain cases, areas like cloud computing and machine learning. The key is to build a strong theoretical foundation and gain practical experience through personal projects, internships, and networking.
How To Become a Data Engineer: A 9-Step Guide

Below, we’ll cover the essential skills you require for a career in the data engineering field and what you can do to impress potential employers.
-
Complete a Course
-
Get Familiar With the Industry and Lay a Solid Foundation
-
Meet the Educational Requirements (And Go Beyond)
-
Learn a Programming Language or Two
-
Nurture the Important Skills
-
Gain Practical Experience by Working on Projects and Building Your Portfolio
-
Your Network Is Your Net Worth (And Can Help You Land a Job)
-
Try To Find a Mentor
-
Pursue an Internship
-
Polish Your Resume Ready and Start Applying
Complete a Course
It’s really difficult – but not impossible – to learn the skills you need to become a data engineer on your own. However, a simple six-month bootcamp is the most affordable, and quickest, way to launch your career without pursuing a formal education. You’ll get all of the help (and the skillset) you need in the most convenient way possible.
Get Familiar With the Industry and Lay a Solid Foundation
Data engineers have to have a love for data and need to understand how it’s employed in the service of real-world problems. But data engineers also need to have a solid understanding of their industry, whether that be finance, healthcare, or marketing. Because while it’s important to know how to work with complex datasets and engineer relational databases, none of that will be very fruitful if you don’t understand the business context to which your work contributes.
Meet the Educational Requirements (And Go Beyond)
A college degree in business analytics, computer science, or mathematics is a great starting point for a career as a data engineer. That said, a college degree is also a costly and time-consuming way to go about picking up these skills.
An alternative is to do a data engineering bootcamp. The advantage of choosing the bootcamp route is that it places a strong emphasis on picking up data engineering skills and you’ll pick up key skills without having to complete classes on any extraneous topics.
Whichever of those paths you choose, you can’t stop learning there. Data engineering is a field with a wide range of analytical approaches and tools used in the trade. So completing data engineering online courses and professional certificates can help you level up.
Learn a Programming Language or Two
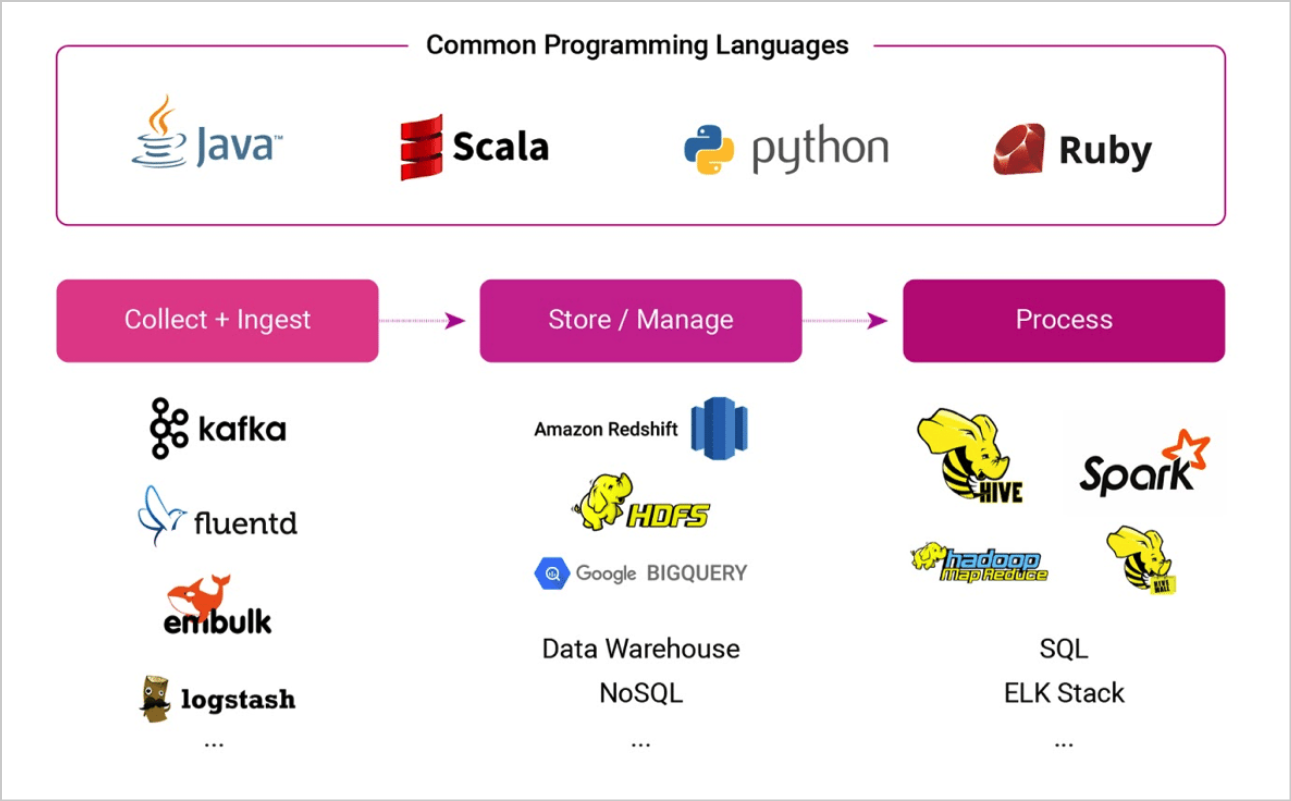
Programming is a skill that you might not always use in your job as a data engineer. But it is one that prospective employers like to see on your resume. Here are a few that you should consider learning:
Python
Python is one of the most commonly used programming languages in data engineering and software engineering in general. If you’re just starting out, it’s a good language to use to understand basic concepts in programming.
SQL
SQL (Server Query Language) is the most popular language that’s used to work with data in relational databases. As a data engineer, it’s essential that you have a knowledge of databases and hands-on experience using SQL to work with them.
Java
Java is a programming language that’s used to build robust cross-platform applications. Software engineers use Java extensively in their work and it has slowly come to be used in data engineering as well.
R
R is a programming language used for statistical analyses. It’s a language that you must be familiar with if you build analytical tools or your work involves a heavy amount of number crunching.
Others
Scala is another popular programming language for working with data. It is extremely good for projects that are data-intensive. Another advantage of Scala is that it runs on the Java virtual machine, which means that you can easily use it to build web apps and mobile services.
Nurture the Important Skills
Programming is only a small part of the broad skill set you require as a data engineer. There are various other in-demand skills in the field. Let’s take a look at what they are.
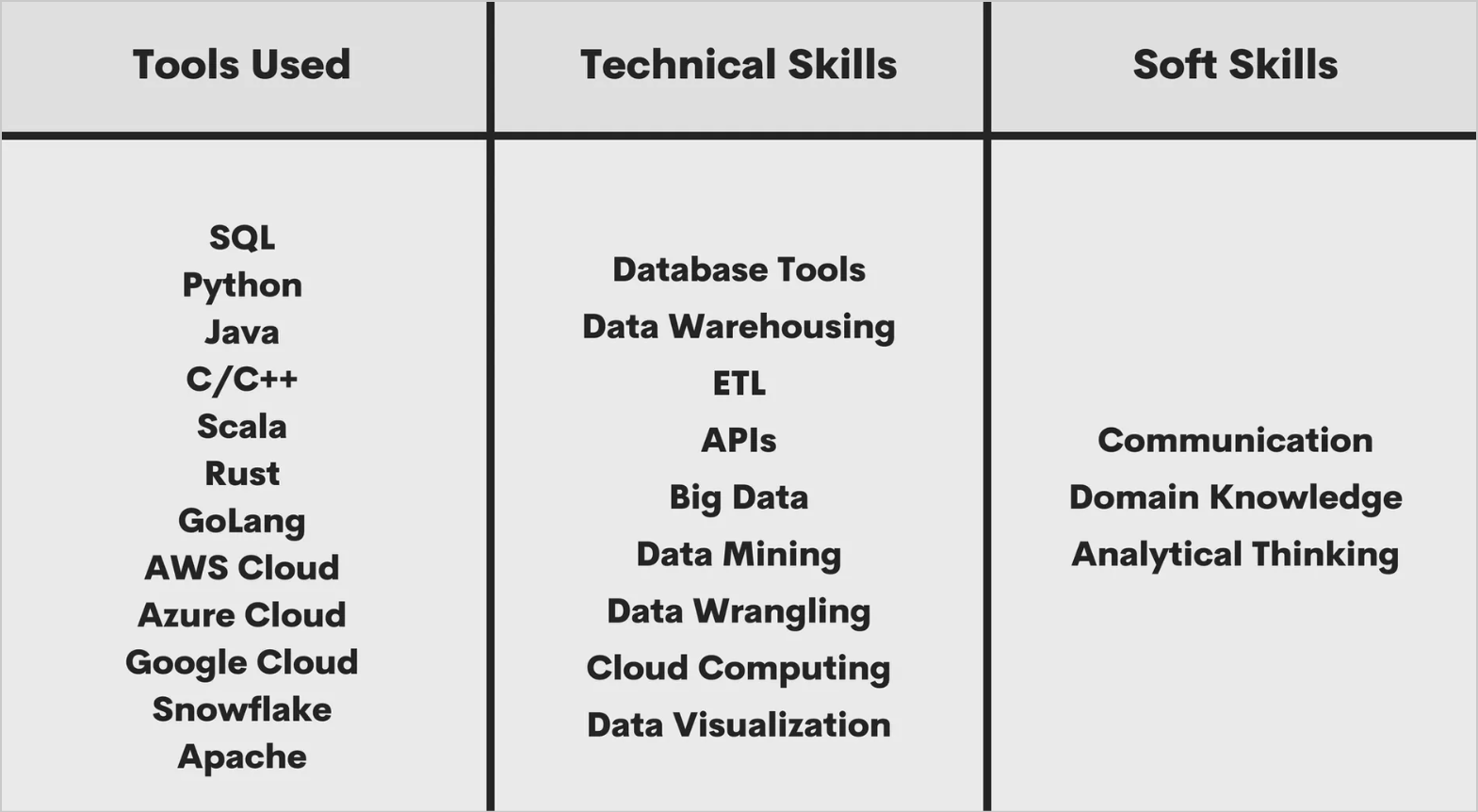
Technical Skills
The most obvious technical skill that data engineers need to have is working with data. You should be adept at data mining, cleaning, and transformation. As you make progress in your career path, you should pick up tools and APIs that help you carry out those processes in an efficient manner.
Data engineers are increasingly required to know the fundamentals of cloud computing. This is because their work often requires working with a cloud-based data warehouse or using cloud data services. So it helps if you have a working knowledge of cloud technology too.
Soft Skills
The job of a data engineer isn’t a straightforward one. You’ll often be thrust into situations where your problem-solving abilities will be tested. You can improve on this skill by working on a wide variety of projects and using new tools and approaches whenever possible.
Data engineering is a collaborative process, and you’ll often have to work with business analysts and project managers to understand the business consequences of your work. This is where communication becomes key. A good data engineer should be able to talk about their work with various stakeholders, even nontechnical ones.
Gain Practical Experience by Working on Projects and Building Your Portfolio
Here are a few ways you can gain some real-world experience and have projects that you can put in your portfolio.
Volunteer Work
Volunteering is perhaps the most low-pressure way to work on real-world projects. It’s not always easy to find volunteer work as a data engineer, though, so you will have to reach out to organizations around you to see if they’re hiring in the field. If you do find such an opportunity, it’s a great way to ease into production work as a data engineer.
Freelance Work
Freelancing as a data engineer, especially a new one, isn’t always easy. You’ll need to choose freelance projects that are limited in scope or where you work under the guidance of a senior engineer.
Sample Projects
Building sample data engineering projects is the best way to gain some practical experience. You can choose to work on something that you’re interested in personally. You can also take things a step forward by putting your code on Github so that others can look at your work and provide feedback.
Get To Know Other Data Science Students

Jonas Cuadrado
Senior Data Scientist at Feedzai

Leoman Momoh
Senior Data Engineer at Enterprise Products

Mikiko Bazeley
ML Engineer at MailChimp
Your Network Is Your Net Worth (And Can Help You Land a Job)
Networking is huge if you want to land a job as a data engineer. Here are a few avenues to build your network as a data engineer:
LinkedIn is great if you want to network, as you don’t have to meet people face-to-face immediately and you can build relationships slowly. But you do need to put effort into nurturing relationships on LinkedIn by engaging with your connections’ posts regularly and posting your own content.
Online Communities
Online communities don’t necessarily give you the opportunity to meet recruiters or senior engineers. But you can meet others who are passionate about data engineering, which can lead to collaborations and referrals.
Here are a few online communities where you can meet other data engineers and other professionals in the field:
Conferences and Meetups
You can check your local Meetup pages and events aggregators for data science and engineering events, which are a great way to meet a broad spectrum of professionals involved in the industry.
Try To Find a Mentor
Mentors help your career in two big ways. The first is that you can learn from their experience in the data engineering industry. The second reason you should pursue mentors is that a good one always gives you personalized feedback. They take the time to understand where your skills stand and what your aspirations are and give you advice that takes those things into account.
Pursue an Internship
Internships look good on your resume and are a great way to learn what data engineering looks like in the real world. To add to that, it’s extremely easy to find data engineering internships on websites like Glassdoor and LinkedIn. You should start applying to these as soon as you’ve completed your basic education and have a budding portfolio.
Polish Your Resume Ready and Start Applying
Make sure that you customize your resume for the kind of job you’re applying to. You don’t want to mention graphic design classes when you’re applying for a role as a data engineer in the healthcare space. This is important because recruiters have very little time to parse each resume and any extraneous elements only lower your chances of getting a call from them.
Becoming a Data Engineer: Where To Start

There are a few different paths you can take on your way to a career in data engineering. Let’s take a look at a few common ones and how you can navigate them.
No Experience
If you’ve got your entire career ahead of you, then you should focus on building your skills and a portfolio. Those two things are basics you can’t miss out on if you want to land a job. But most of all, make sure that you spend time networking and building connections with data engineers, recruiters, and managers in the technology industry.
Related Career Transition
This is perhaps the easiest way to break into the data engineering industry. If you’re in a related career, like business analytics or software engineering, you’ll find that shoring up your skill set isn’t hard. You’ll be able to rely on your existing knowledge base to cover the new aspects that come with a data engineering job.
The first place you should look for a job is at your own company. Most are open to allowing employees to make later career switches. If that’s not the case, then you should start looking for other companies hiring data engineers while working on your own projects.
Unrelated Career Transition
When you come in from an unrelated career, the toughest part is picking up an entirely new skill set. You’ll need to give yourself at least six months to have a functional understanding of data engineering and the ability to work on projects.
Becoming a Data Engineer: Real-Life Examples To Learn From
Johannes Frey
Johannes Frey is a software engineer who made the switch to data engineering about a decade into his career. In this video, he covers the skills you need to pick up to work in data engineering and the courses and certifications that can help along the way. It’s worthwhile to check out the other videos on his channel for technical information and tips on working as a freelancer in data engineering.
Lucaspressie
Here we have the journey of an individual who comes from a sales background. His Medium posts go over the different technical skills you need to pick up and the online courses and other resources that you can use to study them.
How Much Can You Earn as a Data Engineer?
Entry-Level Data Engineer
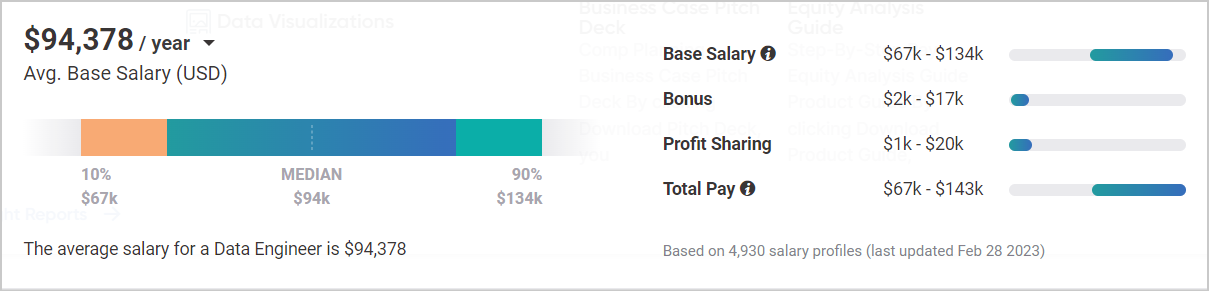
The average salary of entry-level data engineers in the USA is $94,378.
Mid-Level Data Engineer
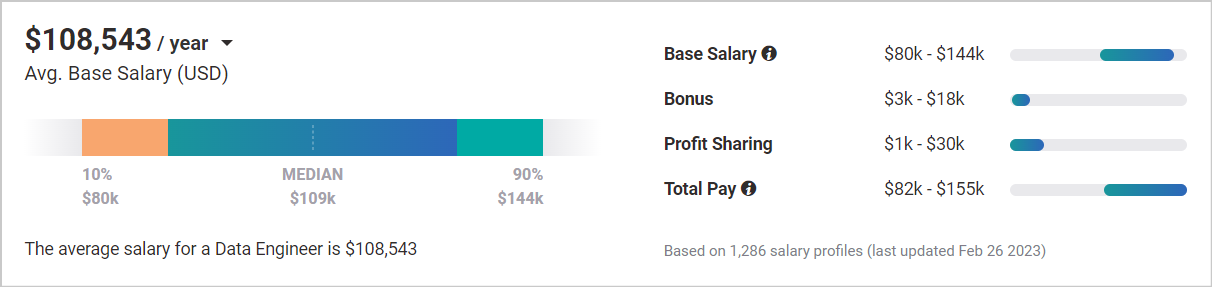
The average salary of mid-level data engineers is $108,543.
Senior Data Engineer
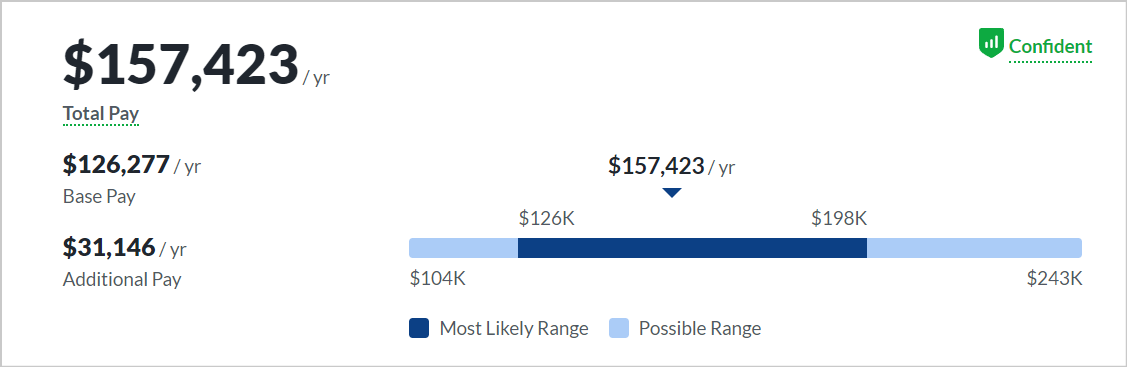
Senior data engineers make an average annual salary of $157,423.
Resources To Find Data Engineering Jobs
Here are a few places where you can find open data engineering roles.
LinkedIn is the best site to find data engineering jobs. It has a simple search function and you can set up alerts for jobs in the industry.
Job Boards
Here are a few job boards where you can find data engineering jobs:
Network
You’ll make things a lot easier for yourself if you build a network for yourself in the data engineering space.
Slack Communities
The following Slack communities post job updates for those looking to enter the data engineering industry.
How To Become a Data Engineer FAQs
We’ve got the answers to your most frequently asked questions:
Is Data Engineering a High-Paying Job?
Yes. In fact, it is among the more lucrative jobs in the data industry.
Can I Become a Data Engineer Without a Degree?
Yes. You can do so by completing a bootcamp and working on building a portfolio of personal projects.
Can I Become a Data Engineer With No Experience?
Yes, but you’ll need to have a college degree or bootcamp under your belt, in addition to a strong portfolio.
Does Data Engineering Require Coding?
Not all data engineers code. That said, most know how to code and often use code to solve problems.
Is Data Engineering the Right Career for Me?
Data engineering can be a great career for you if you’re somebody passionate about using data to solve problems, and if you have the organizational aptitude that’s required to build systems.
Since you’re here…Are you interested in this career track? Investigate with our free guide to what a data professional actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp which will help you land a job or your tuition back!


