
Free UX Design Course
Dive into UX design with our free starter course. Transform your creative ideas into user-friendly solutions.
A software engineer is very familiar with petabytes and XML. Similarly, a doctor is well aware of systolic pressure and the aorta. That’s because these terms belong to their line of work and are frequently tossed around like plain English. UX design is no different. It brings UX terms to the table, ones that you should know as an aspiring designer.
It is easy to get lost if you are not well-versed in the design lingo or familiar with the core principles. To make matters easy for you, here is a compilation of UX terminology that every designer needs to know before traveling further along the UX design career path.

Become A UX Designer. Land a Job or Your Money Back.
Master Adobe XD, Figma, and Sketch. Work 1:1 with an industry mentor. Build a portfolio. Land a job — or your money back.
UX Terms
1. Persona
Often considered a general marketing term, this is frequently used in UX design as well. A persona is a user profile that you develop to get an idea of what the audience wants. In other words, a persona is a representation of the target audience so that you are designing for a specific audience instead of a generic one.
For example, you shouldn’t design a website for seniors with design elements that appeal to millennials. Therefore, a one- or two-page description of your audience covering its goals, behavior patterns, background information, attitude, skills, and working environment is essential.
Here is an example:

(Source)
2. End Users
Whereas a doctor has patients, a service-based business has clients. A UX designer, however, has a different audience: end users. These are the people you will be designing for. So, while a UX design studio has clients, the people at the end of the chain who interact with the design are end users.
3. Pain Points
Pain points are the problems users face that create friction in certain user flows. Once designers identify these, they can create a user-friendly design. A UX case study shares how user pain points were dug out and how design solved them, as shown below:

(Source.)
4. User Research
User research is one of the more self-explanatory UX design terms. It is all the research that you conduct to understand your end user better. UX Booth defines user research as “a variety of investigative methods used to add context and insight to the design process.”
The process incorporates analytical tasks such as quantitative and qualitative research. Quantitative research relates to gathering numerical data to understand user behavior.
On the flip side, qualitative research is a descriptive attempt to understand the target audience’s problems, motivations, opinions, and reasons via processes such as interviews.

Read more on becoming a user researcher here.
5. UI Elements
User Interface (UI) elements are virtual items on a website’s interface that allow users to engage with the design. Examples of such items include buttons, slider arrows, navigation bars, dropdown lists, message boxes, and anything that enables users to navigate through a website.
Here’s an example of a dropdown list:

6. User-Centered Design (UCD)
Another frequently used UX term is user-centered design. It emphasizes the end user throughout the design and development process. The goal is to produce a design that aligns with the wants and needs of the user. To this end, UCD revolves around continuously researching, testing, and checking features within the product to deliver a design that appeals to users.

7. Experience Architecture
Experience architecture is a map that lays the outline of the path that a user will take from the start to the intended goal. It is a combination of several UX and design processes:
- Information architecture: chalking out and designing an information model
- Interaction design: developing a structure and pattern of actions or behaviors for a design and its users
- Experience design: working out how a design will function across multiple platforms
Get To Know Other Design Students

Kelly Hart
UX/UI Designer at Perficient

Parker Konz
Visual Designer at Gorilla Group

April Hoang
UX Designer at Microsoft
8. Breadcrumbs
If breadcrumbs bring the Grimm Brothers’ famous fairytale of Hansel and Gretel to mind, then you are on the right page. Because the term breadcrumbs in design lingo is also borrowed from the fairy tale.
Breadcrumbs are secondary navigation aids that tell users where they are on a website. These allow users to retrace their steps on multilevel websites. Despite their secondary status, breadcrumbs have been in use since 1995, helping make designs user-friendly.
Here is an example:
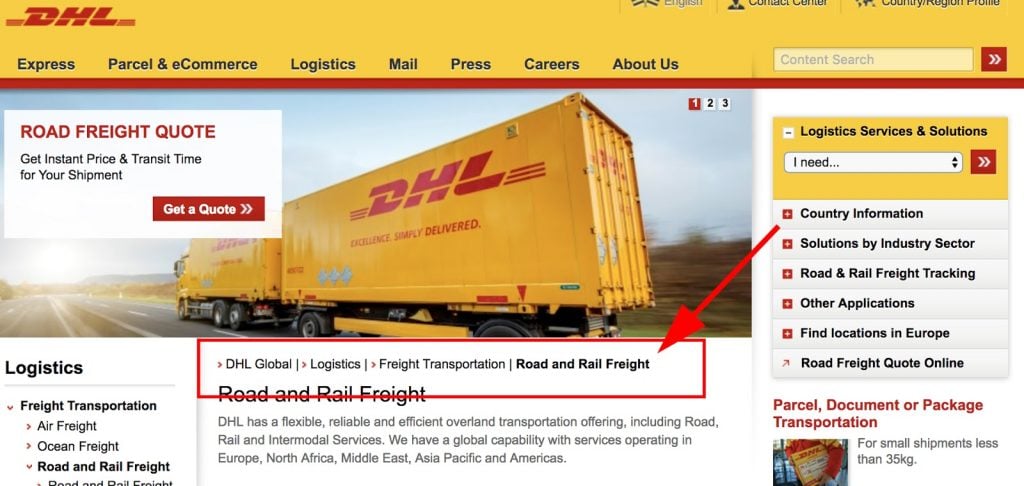
(Source.)
9. Wireframe
A wireframe is a skeletal framework of your product, app, or website design. It is a blueprint of the design without any content, images, and interactive elements. The purpose of a wireframe is to lay out the functionality and content of the page, showing where a design element will be present on the screen.
Wireframes are made in the early development phase before a prototype is created to establish a basic structure of the page before any design elements are added to it.

10. Prototype
A prototype is an outline of the proposed final product that is used for testing before launch. Low-level prototypes showcase a bare-bones sketch of how a design will look. High-level prototypes, on the other hand, add more details to the sketch, but aren’t full-design mockups.

11. Mockup
A mockup is a realistic representation of how the design will finally look in the end. Bear in mind that a mockup looks exactly like the final product. This means that it is formed after all the revisions to the design have been made.
Here is what a mockup looks like:
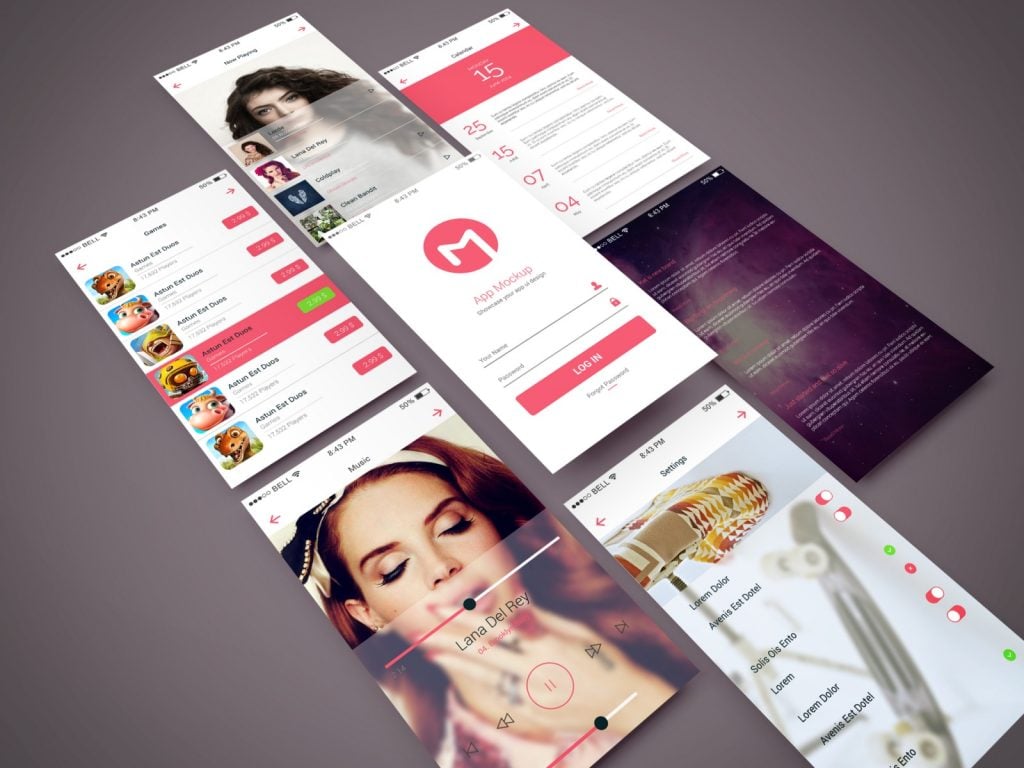
(Source.)
12. A/B Testing
A/B testing is also referred to as split testing. It is the process that asks users to pick from two versions of your design. The products are presented side by side to a group of users to learn which they like better.
The aim is to test different versions of a product simultaneously to learn about the differences in user preference and behavior between the two. A/B tests are conducted when a working model of the design has been framed.
Here is a comparison test between two sample pages:

(Source.)
13. Card Sorting
Card sorting is a user research method that asks users to arrange information into groups that make sense to them. The card sorting technique allows you to develop an effective, user-friendly sitemap and information architecture. You use pieces of paper, cards, or an online card sorting tool to get started with this research technique.

14. Data-Driven Design
Design that is backed by data and helps understand the target audience better is known as data-driven design. Data helps prove, reveal, and improve your design. It proves that your work is on the right track, it reveals the users’ pain points and opportunities while unearthing new trends, and it improves your designs by adding objectivity to them.

(Source.)
15. Flat Design
Flat design is a UI design style that focuses on employing simple, two-dimensional elements with bright colors. Nick Babich of UX Planet calls flat design a “more sophisticated cousin of minimalism” as all the UI elements are based on simplicity.
Dropbox’s website gives a good example of flat design, with the UI elements observing minimalism to shine a spotlight on the page’s content:

(Source.)
16. Interaction Design
Interaction design is a type of web design that is centered around creating an engaging interface with logical actions and behaviors. Successful interaction design is based on the use of technology and a clear understanding of good communication to create the desired user experience.

17. Iterative Design
Iterative design is a design methodology that is not limited by a clear start or stop. Instead, it is a cyclical method of design that involves prototyping, planning, implementing, testing, and then repeating the process. Based on the results of the tests, changes are made to prepare a design that suits users the best.

18. Mood board
A mood board is a collection of materials and assets that help define the specific style for a product (such as a website or an app) using images, text, colors, and other branding elements. It gives an insight into the voice, direction, language, and style of a particular project, design, or brand. Unlike most other step-wise data collection methods, a mood board is free-flowing by nature.
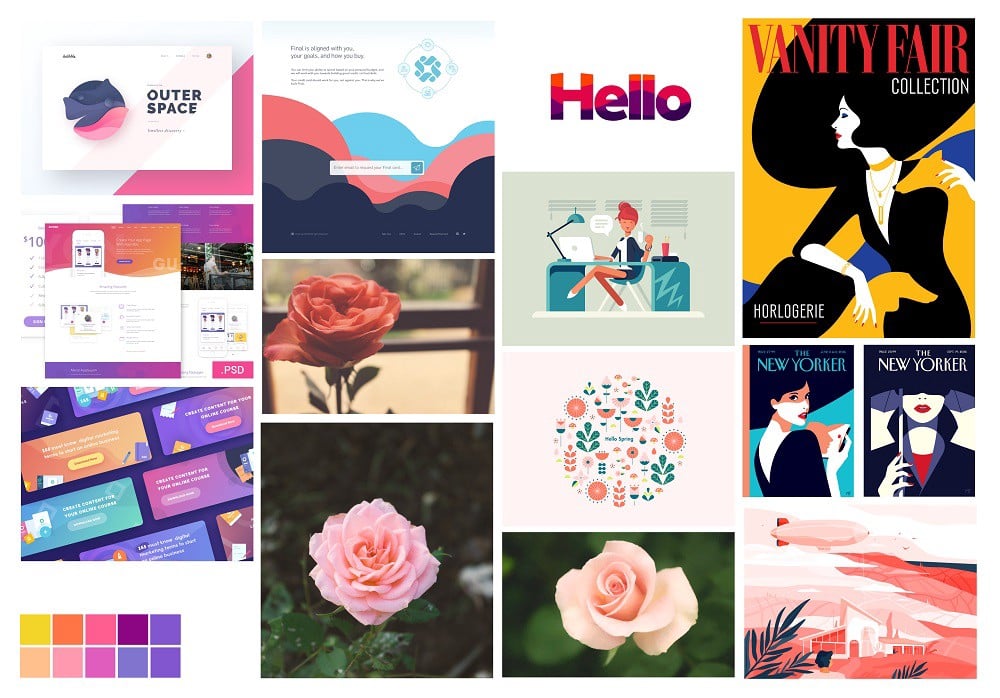
(Source.)
19. Storyboard
A storyboard is a rough sketch of a scenario. A storyboard captures a UX designer’s vision of what a design will look like. The Nielsen Norman Group highlights that a storyboard communicates a story via sequenced images that are arranged chronologically to narrate a story’s main events.
Here is a look at a storyboard that covers a daily life scenario in which a product is used:

(Source.)
20. User Journey
A user journey is a chain of steps established by a UX designer to demonstrate where site visitors enter and how they interact with a design. A user journey is also referred to as UX flow. It is established for two chief purposes. First, user journeys trace steps users are currently taking when interacting with a service, design, or product. Second, user journeys establish a flow that visitors could follow when interacting with a design, product, or service.
21. Usability Test
Usability among UX design terms refers to the ease of navigating through a design. So, usability testing asks users to complete tasks while a researcher observes them to learn about any problems or confusion encountered when interacting with the design.

(Source.)
22. Eye Tracking
Eye tracking is gaining a lot of prominence as a research technique. As its name suggests, the method employs tools to track eye movements of the users to learn where they look at a design, website, or any other visual data. It sheds light on which visuals attract the greatest user attention.
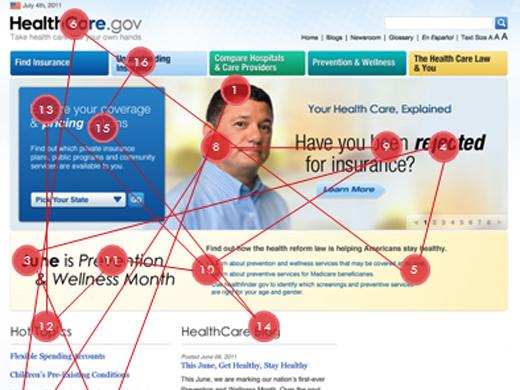
(Source.)
23. KPIs
KPIs stand for key performance indicators. These study the trends prevailing over a duration, usability patterns, and sketch comparisons with competitors as well. The end result is to gather data on how well the users are interacting with a design and whether or not it succeeded in fulfilling the designer’s expectations.
24. Conversion Rate
A conversion rate is the percentage of users who take the desired action. Essentially, the conversion rate shows how effective your design is in convincing people to take action. A classic example is that of an e-commerce website that converts its site visitors into paying customers, as pictured below. The task of improving this conversion rate is known as conversion rate optimization.
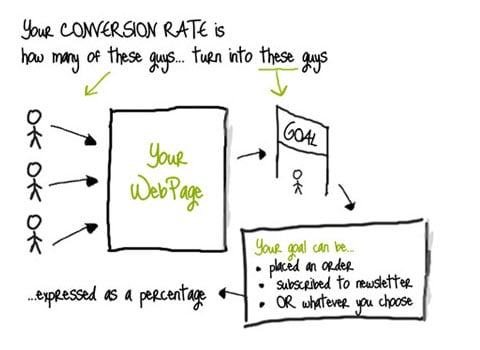
(Source.)
25. Widget
A widget is an on-screen element that users interact with. For example: social media icons, sliders, buttons, and contact forms, to name a few.
Since you’re here
If you want to work in design, you can. It’s that simple. With our UX Bootcamp, we’ll help you launch your design career in 9 months or less. Browse our free UX salary guide to see what you could be making


