
According to the U.S. Bureau of Labor Statistics, “data scientist” positions are growing at a faster than average pace, with projected 35% growth by 2032.. Coupled with a median salary of $131,490, it’s never been a better time to get into the field of data science.
But changing careers is not something that can be done overnight. From education and portfolio-building to networking and interviewing, there are several steps budding data scientists must take before they are ready for their first day on the job.
How to Become a Data Scientist
The following list outlines the steps required to become a data scientist in today’s market. Each step includes a link to the corresponding section below, in which we outline each one in greater detail:
1. Start with a Prep Course
If you are completely new to the field, it’s best to start with an introductory prep course into data science. You’ll learn a lot about the tools you’ll use, the industry, and what your day-to-day working life might be like.
2. Brush Up on Data Science Fundamentals
The obvious place to start when considering how to become a data scientist is assessing what you know and what you don’t. Niches and specialties cannot be developed until the fundamentals of the trade have been perfected, so starting simple is never a waste of time!
Here’s where you should focus your energy:
- Statistical Analysis. This includes analyzing data and presenting the findings through unbiased and accurate statistics.
- Programming. Writing code and building software are key skills in many areas of data science.
- Data Visualization. Presenting data in tables, graphs, charts, or dashboards ensures that it can be quickly and easily comprehended by both technical and non-technical individuals.
- Machine Learning. Create software that “learns” from the data it ingests and uses it to spontaneously adapt its processes in response to unique situations.
Get To Know Other Data Science Students

Garrick Chu
Contract Data Engineer at Meta

George Mendoza
Lead Solutions Manager at Hypergiant

Leoman Momoh
Senior Data Engineer at Enterprise Products
3. Meet the Educational Requirements
Don’t worry – you don’t need a college degree to become a data scientist, but there are some educational requirements you need to be aware of before you attempt to land your first data science job.
- You Don’t Need a Degree in Data Science, But a Bachelor’s Degree Can Be Helpful. Data science degrees are still relatively new college programs that combine elements of mathematics, computer science, statistics, and business science. As such, a separate or advanced degree in any of these or other relevant fields is a perfectly acceptable educational background for a data scientist.
- Take a Certified Course or a Bootcamp. If you are considering how to become a data scientist without a college degree, the best options are to look at secondary certifications. Taking a certified course or enrolling in a data science bootcamp is a great way to get an immersive, hands-on, and practical education in the fundamentals of the subject of data science and, more specifically, in the role of a data scientist.
4. Plan Your Career Path and Specialization
Once you have the fundamentals under control, you can begin to plan a path for yourself and develop a niche or specialization that can give you an edge when you’re in the job market.
Related Read: 14 Data Science Careers to Consider [Skills, Salary, Role]
5. Hone Essential Skills
Earning certifications in data science or developing your own data science projects to showcase the list of skills below is a great way to demonstrate your ability.
Technical Skills
IT professionals who work with computers every day can save themselves time and effort if they knowhow to troubleshoot problems with some of these general technical skills.
- Programming Languages. A data scientist is expected to be fluent in Python, and generally familiar with other languages like R or SQL.
- Data Mining. Data mining is the gathering of relevant and trustworthy data from different sources and formats and often includes third parties, as well.
- Data Visualization. Getting a grip on data visualization tools like Tableau, Microsoft Excel, and Google Charts to display data in readable ways is a key skill for data scientists.
- Data Analysis. Querying and analyzing structured data can help identify patterns and points of interest that translate into actionable insights and business opportunities.
- Statistics. Statistics can provide unbiased insights based purely on numbers and data to help decision-makers separate fiction and feeling from fact when forming business plans.
- Machine Learning. Once you have studied the fundamental concepts behind machine learning, you may want to pursue it as a specialization, which means furthering your study and working on your own machine learning projects.
- Deep Learning. Deep learning is a branch of machine learning that focuses on replicating certain learning methods that ingest and reinforce information via artificial neural networks that resemble human neurons.
- Natural Language Processing. Another branch of machine learning, natural language processing (NLP) is widely used for virtual assistants like Apple’s Siri or Amazon’s Alexa.
- Algorithms. Algorithms are sets of instructions that solve problems and perform computations. AI programs utilize these algorithms to automate business processes or perform various functions, depending on the unique instance they are employed for.
- Data Engineering. Data engineering includes every data-related skill, from gathering data to wrangling and cleaning it — basically all the steps prior to analysis.
Soft Skills
Data scientists must communicate their findings to employees beyond the scope of their data science teams, which means explaining their insights to people who lack the same knowledge or skill sets. This requires highly developed soft skills – also called people skills – in communication and presentation.
- Analytical Mindset. Data science isn’t just about finding the right answers from data sets, but also about forming insightful questions, which requires an analytical mindset.
- Business Acumen. Many data scientists work with the goal of improving the company they work for, whether that means improving efficiency, raising profits, coming up with profitable ideas, or finding new ways to save money. In addition to being able to read the data, data scientists need to understand what a business needs.
- Critical Thinking. Critical thinking helps root out anomalies and incorrect values in data sets, and is therefore particularly useful for the data cleaning and wrangling process.
- Adaptability and Flexibility. Data is what it is, not what we want it to be, which means it may not always show us the information we want to see. When hiccups occur, adaptability and flexibility are key to overcoming problems and turning them into something useful.
- Collaboration And Teamwork. Data scientists usually work within a team and so must be able to work well with others. They also need to collaborate with other departments to collect data and share their findings.
- Problem-Solving. Being a self-starter is a valuable trait for data scientists. Working on solutions and improving your problem-solving skills will make you a great asset to any team.
- Communication. When a problem needs to be shared, a deadline extended, or a plan changed, swift and clear communication is key to maintaining a happy team and a healthy project.
- Patience And Persistence. Sifting through data can be a time-consuming process, and patterns will not always jump out willingly. Patience is key to finding those all-important actionable insights.
6. Familiarize Yourself With the Essential Data Science Tools
Here is a list of popular tools used in the field of data science so that you can familiarize yourself with them.
- Apache Spark. An analytics engine used for large-scale data engineering, processing, and machine learning.
- Tableau. A data visualization tool that connects to databases and allows users to create powerful and varied visual representations of their data.
- SAS. A statistical software suite designed to help users manage, analyze, predict, and visualize data.
- MATLAB. A programming language used to develop algorithms and create models.
- Python. Python is a programming language designed for readability and used frequently by 75% of data scientists.
- R. A statistical programming language used by 47% of data scientists.
- BigML. A popular machine learning platform.
7. Gain Practical Experience by Working on Projects and Building Your Portfolio
Developing a large, impressive, and detailed portfolio is a great way to showcase your ability and passion, especially if you lack formal education or experience. Creativity and individualism are highly valued, so you can choose from any and all data science projects that may interest you.
8. Build Your Network
Building your network is a good way to get your foot in the door when you’re first starting out. It will help you develop your skills, make friends with similar interests, work on your passion projects, and finally, find a data science job.
- LinkedIn. Linkedin is a useful tool if you use it correctly. Always connect with colleagues and acquaintances you make within the industry, even those with whom you simply attended an event.
- Online Communities. Online professional and amateur communities on platforms like Discord and Reddit are great places to exchange ideas.
- Conferences and Meet-Ups. Becoming an active member of your local data science community doesn’t have to come after you’ve landed the job and made a name for yourself. Start attending conferences and meet-ups as soon and as often as you are able.
9. Pursue a Data Science Internship
If you are lucky enough that you can work for free or for limited pay, look into getting a data science internship to complement your study with real-life experience.
10. Prepare for and Ace the Data Science Interview
When preparing for a data science interview, research is key. Research the company, the people, the role, typical data science interview questions, and questions you should ask the interviewer.
Popular Roles Within Data Science
Here is a breakdown of some of the most popular roles and titles within the field of data science.
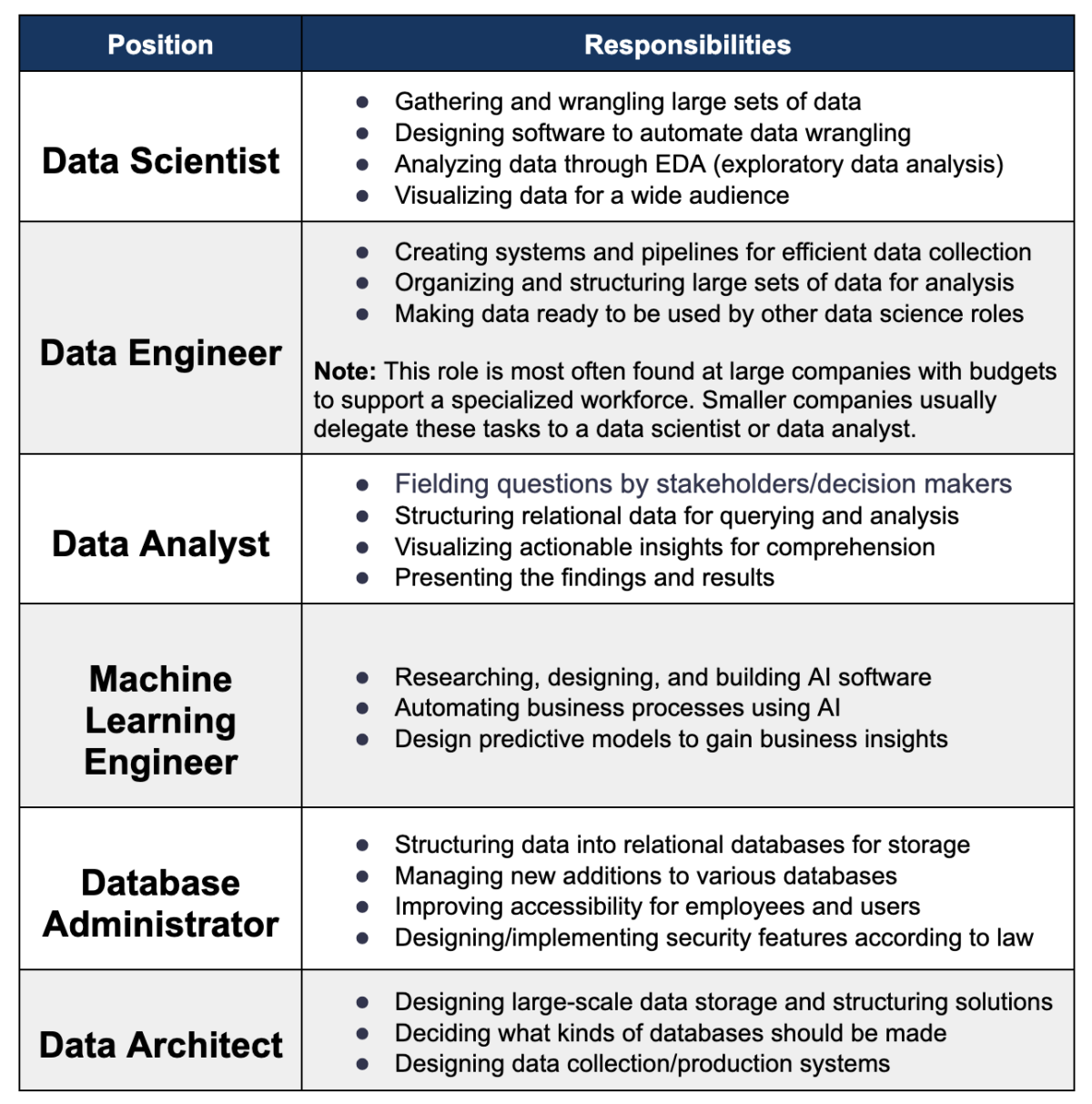
Data Scientist Salary: How Much Can You Make?
Here are some average salaries for data scientists at different stages in their careers.
Entry-Level Data Scientist
For a data scientist’s first role, the average salary sits at around $110,179. However, even in your first data science or analysis role, salary negotiation is possible.

Related Read: 7 Entry-Level Data Science Jobs
Mid-Level Data Scientist
Mid-level data scientists have around 2-4 years of experience and can expect to earn about $120,256.

Senior-Level Data Scientist
Senior-level professionals who are around 5-7 years into their data science careers can expect to earn around $150,910 annually. However, Glassdoor reports a top threshold of $307,000.

How to Become a Data Scientist – The Next Steps
If you’re still wondering how to become a data scientist after reading all the steps above, we understand – the process is long and often confusing. A great place to start if you aren’t sure is with a reputable data science bootcamp. The courses offered by Springboard are comprehensive and provide graduates with the essential resources and skills to grow their careers, as well as the industry knowledge to identify the best path for them.
Companies are no longer just collecting data. They’re seeking to use it to outpace competitors, especially with the rise of AI and advanced analytics techniques. Between organizations and these techniques are the data scientists – the experts who crunch numbers and translate them into actionable strategies. The future, it seems, belongs to those who can decipher the story hidden within the data, making the role of data scientists more important than ever.
In this article, we’ll look at 13 careers in data science, analyzing the roles and responsibilities and how to land that specific job in the best way. Whether you’re more drawn out to the creative side or interested in the strategy planning part of data architecture, there’s a niche for you.
Is Data Science A Good Career?
Yes. Besides being a field that comes with competitive salaries, the demand for data scientists continues to increase as they have an enormous impact on their organizations. It’s an interdisciplinary field that keeps the work varied and interesting.
10 Data Science Careers To Consider
Whether you want to change careers or land your first job in the field, here are 13 of the most lucrative data science careers to consider.
Data Scientist
Data scientists represent the foundation of the data science department. At the core of their role is the ability to analyze and interpret complex digital data, such as usage statistics, sales figures, logistics, or market research – all depending on the field they operate in.
They combine their computer science, statistics, and mathematics expertise to process and model data, then interpret the outcomes to create actionable plans for companies.
General Requirements
A data scientist’s career starts with a solid mathematical foundation, whether it’s interpreting the results of an A/B test or optimizing a marketing campaign. Data scientists should have programming expertise (primarily in Python and R) and strong data manipulation skills.
Although a university degree is not always required beyond their on-the-job experience, data scientists need a bunch of data science courses and certifications that demonstrate their expertise and willingness to learn.
Average Salary
The average salary of a data scientist in the US is $156,363 per year.
Data Analyst
A data analyst explores the nitty-gritty of data to uncover patterns, trends, and insights that are not always immediately apparent. They collect, process, and perform statistical analysis on large datasets and translate numbers and data to inform business decisions.
A typical day in their life can involve using tools like Excel or SQL and more advanced reporting tools like Power BI or Tableau to create dashboards and reports or visualize data for stakeholders. With that in mind, they have a unique skill set that allows them to act as a bridge between an organization’s technical and business sides.
General Requirements
To become a data analyst, you should have basic programming skills and proficiency in several data analysis tools. A lot of data analysts turn to specialized courses or data science bootcamps to acquire these skills.
For example, Coursera offers courses like Google’s Data Analytics Professional Certificate or IBM’s Data Analyst Professional Certificate, which are well-regarded in the industry. A bachelor’s degree in fields like computer science, statistics, or economics is standard, but many data analysts also come from diverse backgrounds like business, finance, or even social sciences.
Average Salary
The average base salary of a data analyst is $76,892 per year.
Business Analyst
Business analysts often have an essential role in an organization, driving change and improvement. That’s because their main role is to understand business challenges and needs and translate them into solutions through data analysis, process improvement, or resource allocation.
A typical day as a business analyst involves conducting market analysis, assessing business processes, or developing strategies to address areas of improvement. They use a variety of tools and methodologies, like SWOT analysis, to evaluate business models and their integration with technology.
General Requirements
Business analysts often have related degrees, such as BAs in Business Administration, Computer Science, or IT. Some roles might require or favor a master’s degree, especially in more complex industries or corporate environments.
Employers also value a business analyst’s knowledge of project management principles like Agile or Scrum and the ability to think critically and make well-informed decisions.
Average Salary
A business analyst can earn an average of $84,435 per year.
Database Administrator
The role of a database administrator is multifaceted. Their responsibilities include managing an organization’s database servers and application tools.
A DBA manages, backs up, and secures the data, making sure the database is available to all the necessary users and is performing correctly. They are also responsible for setting up user accounts and regulating access to the database. DBAs need to stay updated with the latest trends in database management and seek ways to improve database performance and capacity. As such, they collaborate closely with IT and database programmers.
General Requirements
Becoming a database administrator typically requires a solid educational foundation, such as a BA degree in data science-related fields. Nonetheless, it’s not all about the degree because real-world skills matter a lot. Aspiring database administrators should learn database languages, with SQL being the key player. They should also get their hands dirty with popular database systems like Oracle and Microsoft SQL Server.
Average Salary
Database administrators earn an average salary of $77,391 annually.
Data Engineer
Successful data engineers construct and maintain the infrastructure that allows the data to flow seamlessly. Besides understanding data ecosystems on the day-to-day, they build and oversee the pipelines that gather data from various sources so as to make data more accessible for those who need to analyze it (e.g., data analysts).
General Requirements
Data engineering is a role that demands not just technical expertise in tools like SQL, Python, and Hadoop but also a creative problem-solving approach to tackle the complex challenges of managing massive amounts of data efficiently.
Usually, employers look for credentials like university degrees or advanced data science courses and bootcamps.
Average Salary
Data engineers earn a whooping average salary of $125,180 per year.
Database Architect
A database architect’s main responsibility involves designing the entire blueprint of a data management system, much like an architect who sketches the plan for a building. They lay down the groundwork for an efficient and scalable data infrastructure.
Their day-to-day work is a fascinating mix of big-picture thinking and intricate detail management. They decide how to store, consume, integrate, and manage data by different business systems.
General Requirements
If you’re aiming to excel as a database architect but don’t necessarily want to pursue a degree, you could start honing your technical skills. Become proficient in database systems like MySQL or Oracle, and learn data modeling tools like ERwin. Don’t forget programming languages – SQL, Python, or Java.
If you want to take it one step further, pursue a credential like the Certified Data Management Professional (CDMP) or the Data Science Bootcamp by Springboard.
Average Salary
Data architecture is a very lucrative career. A database architect can earn an average of $165,383 per year.
Machine Learning Engineer
A machine learning engineer experiments with various machine learning models and algorithms, fine-tuning them for specific tasks like image recognition, natural language processing, or predictive analytics. Machine learning engineers also collaborate closely with data scientists and analysts to understand the requirements and limitations of data and translate these insights into solutions.
General Requirements
As a rule of thumb, machine learning engineers must be proficient in programming languages like Python or Java, and be familiar with machine learning frameworks like TensorFlow or PyTorch. To successfully pursue this career, you can either choose to undergo a degree or enroll in courses and follow a self-study approach.
Average Salary
Depending heavily on the company’s size, machine learning engineers can earn between $125K and $187K per year, one of the highest-paying AI careers.
Quantitative Analyst
Qualitative analysts are essential for financial institutions, where they apply mathematical and statistical methods to analyze financial markets and assess risks. They are the brains behind complex models that predict market trends, evaluate investment strategies, and assist in making informed financial decisions.
They often deal with derivatives pricing, algorithmic trading, and risk management strategies, requiring a deep understanding of both finance and mathematics.
General Requirements
This data science role demands strong analytical skills, proficiency in mathematics and statistics, and a good grasp of financial theory. It always helps if you come from a finance-related background.
Average Salary
A quantitative analyst earns an average of $173,307 per year.
Data Mining Specialist
A data mining specialist uses their statistics and machine learning expertise to reveal patterns and insights that can solve problems. They swift through huge amounts of data, applying algorithms and data mining techniques to identify correlations and anomalies. In addition to these, data mining specialists are also essential for organizations to predict future trends and behaviors.
General Requirements
If you want to land a career in data mining, you should possess a degree or have a solid background in computer science, statistics, or a related field.
Average Salary
Data mining specialists earn $109,023 per year.
Data Visualisation Engineer
Data visualisation engineers specialize in transforming data into visually appealing graphical representations, much like a data storyteller. A big part of their day involves working with data analysts and business teams to understand the data’s context.
General Requirements
Data visualization engineers need a strong foundation in data analysis and be proficient in programming languages often used in data visualization, such as JavaScript, Python, or R. A valuable addition to their already-existing experience is a bit of expertise in design principles to allow them to create visualizations.
Average Salary
The average annual pay of a data visualization engineer is $103,031.
Resources To Find Data Science Jobs
The key to finding a good data science job is knowing where to look without procrastinating. To make sure you leverage the right platforms, read on.
Job Boards
When hunting for data science jobs, both niche job boards and general ones can be treasure troves of opportunity.
Niche boards are created specifically for data science and related fields, offering listings that cut through the noise of broader job markets. Meanwhile, general job boards can have hidden gems and opportunities.
Online Communities
Spend time on platforms like Slack, Discord, GitHub, or IndieHackers, as they are a space to share knowledge, collaborate on projects, and find job openings posted by community members.
Network And LinkedIn
Don’t forget about socials like LinkedIn or Twitter. The LinkedIn Jobs section, in particular, is a useful resource, offering a wide range of opportunities and the ability to directly reach out to hiring managers or apply for positions. Just make sure not to apply through the “Easy Apply” options, as you’ll be competing with thousands of applicants who bring nothing unique to the table.
FAQs about Data Science Careers
We answer your most frequently asked questions.
Do I Need A Degree For Data Science?
A degree is not a set-in-stone requirement to become a data scientist. It’s true many data scientists hold a BA’s or MA’s degree, but these just provide foundational knowledge. It’s up to you to pursue further education through courses or bootcamps or work on projects that enhance your expertise. What matters most is your ability to demonstrate proficiency in data science concepts and tools.
Does Data Science Need Coding?
Yes. Coding is essential for data manipulation and analysis, especially knowledge of programming languages like Python and R.
Is Data Science A Lot Of Math?
It depends on the career you want to pursue. Data science involves quite a lot of math, particularly in areas like statistics, probability, and linear algebra.
What Skills Do You Need To Land an Entry-Level Data Science Position?
To land an entry-level job in data science, you should be proficient in several areas. As mentioned above, knowledge of programming languages is essential, and you should also have a good understanding of statistical analysis and machine learning. Soft skills are equally valuable, so make sure you’re acing problem-solving, critical thinking, and effective communication.
Since you’re here…Are you interested in this career track? Investigate with our free guide to what a data professional actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp which will help you land a job or your tuition back!


