According to Gartner, 85 percent of machine learning projects fail, leaving most organizations without a positive ROI.
To avoid spending unnecessary time, money, and energy reinventing the wheel, many organizations have started employing machine learning frameworks. These frameworks simplify the process of algorithm development for engineers, making ML easier, more scalable, and more accessible.
Machine learning frameworks support basic tensor operations (math behind algorithms), automatic differentiation (to prevent calculation errors through backpropagation, a method of doing forward and then backward passes to compute the gradient), and systems techniques, like minibatching and Adam optimization.
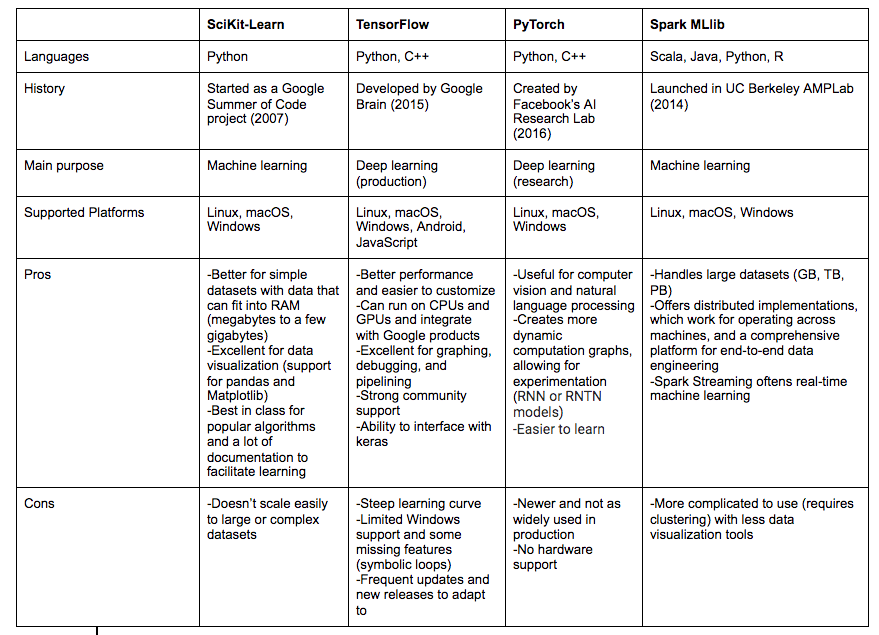
The most popular machine learning frameworks have strong community support, usually with major company backing. Which framework you choose, depends on your goals: what problem you’re looking to solve, how much experience you have, and how quickly you need results.
Want to learn more about becoming a machine learning engineer? Check out Springboard’s comprehensive career guide here.
Four key machine learning frameworks
Here’s an overview of four key frameworks:
SciKit-Learn
SciKit is a popular free machine learning library in Python that is built on NumPy, (an extremely important library for data scientists and machine learning enthusiasts) SciPy, and matplotlib. You can use it for classification, regression, clustering, dimensionality reduction, model selection, K-nearest neighbor, support-vector machines (SVMs), stochastic gradient descent models, and preprocessing (feature extraction and normalization).
More reading: How a Machine Learning Algorithm Helped Make Hurricane Damage Assessments Safer, Cheaper, and More Effective
This tutorial walks you through the process of importing the Sales_Win_Loss data set from IBM’s Watson repository with the pandas module and using Scikit-learn to create a model to predict the effectiveness of various sales campaigns.
This is an example of displaying data with the head() method. The tail() method is similar, but it returns the last few records instead.

To investigate the different data types, use the dtypes() method.

After you explore the data, you can then set up data visualization in libraries like Seaborn.

Scikit is accessible and easy to learn for beginners, but not necessarily as well-suited for deep learning as some of the other frameworks.
Looking for more information on SciKit-Learn? Check out our complete guide to SciKit-Learn with a logistic regression example.
Get To Know Other Data Science Students

Leoman Momoh
Senior Data Engineer at Enterprise Products

Samuel Okoye
IT Consultant at Kforce

Jonas Cuadrado
Senior Data Scientist at Feedzai
TensorFlow
Designed by Google, TensorFlow is an open-source library for numerical computation and machine learning, which can work with CPU and GPU. It allows you to handle regression, classification, and neural network problems.
Neural networks follow a typical structure.
You can build neural network models using the Keras programming interface. Easy to use with a simple API, Keras allows you to classify images and text. It can also scale to solve more complex problems, with the ability to adapt to multiple programming languages (Python, Javascript, C++, Java, Go).
This example analyzes sentiment from a dataset of 40,000 Tweets. After processing and vectorizing the Tweets, the first step involves subclassing the tf.keras. Model class, defining layers in the __init__() method, and creating a forward pass method using the call method.
With input or output tensors, you can also create functional or sequential model APIs.
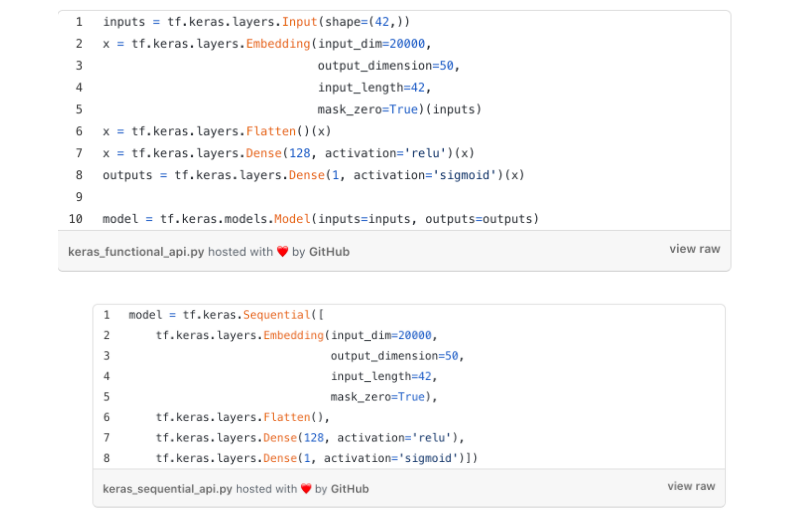
Here is a basic snippet of TensorFlow machine learning code and a walkthrough of how to build a simple model from scratch:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation=‘relu’),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=‘softmax’)
])
model.compile(optimizer=‘adam’,
loss=‘sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
TensorFlow is ideal in many cases because you can find a repository of already implemented models on Github. It also performs deep learning through neural networks and provides visualizations through TensorBoard, generating everything from distributions and histograms to audio files.
For coders with different levels of expertise, here are some additional tutorials that run on Jupyter notebooks and in Google Colab.
Looking for more information about TensorFlow? Check out our guide to PyThorch vs. TensorFlow.
PyTorch
Used by Facebook, PyTorch is a framework designed for computer vision, reinforcement learning, and natural language processing and is frequently the tool of choice for rigorous research.
On the PyTorch website, you can also find tutorials on constructing neural networks. These case studies show how to classify handwritten digits, objects, sentiments, and images.
This tutorial walks through the example of fitting y=sin(x) with a third-order polynomial and training a network of four parameters with gradient descent “to fit random data by minimizing the Euclidean distance between the network output and the true output.”
It builds off of NumPy—in fact, a PyTorch Tensor is an n-dimensional array similar to the NumPy array, but Tensors can use GPUs to make the speed 50x faster.

Several useful PyTorch packages and libraries provide a framework for accomplishing different tasks. In the example above, you need to manually implement forward and backward passes, but it is possible to automate with the autograd package.
The nn package serves a similar function to the Keras, TensorFlow-Slim, and TFLearn packages, by creating Modules (like neural network layers), which receive input Tensors and produce output Tensors.
You can update the weights of models manually by using learning parameters like torch.no_grad(), but the optim package and other optimizers, such as AdaGrad, RMSProp, and Adam, will make this work more scalable.
PyTorch is more challenging to learn than TensorFlow, but it is easier to customize and faster to train.
Looking for more information about PyTorch? Check out our guide to PyThorch vs. TensorFlow.
Spark MLlib
Founded in 2009 at UC Berkeley, Spark is a unified analytics engine and open-source cluster-computer framework that can write applications in Java, Scala, Python, R (a popular programming language in the domain of data science to do statistical analysis), and SQL and run on Hadoop, Apache Mesos, Kubernetes or in the cloud. It can also run on a standalone cluster. The basic architecture includes drivers converting code into tasks and executors. Executors run on the nodes containing the tasks and put the nodes to work.
Spark has a machine learning library called MLlib, which performs functions like classification, regression, clustering, optimization, dimensionality reduction, collaborative filtering, and feature extraction and transformation.
This tutorial builds off of a Boston Housing dataset. The goal is to use the 14 features, which consist of CRIM (per capita crime rate), RM (average number of rooms per dwelling), PTRATIO (pupil-teacher ratio by town), NOX (nitric oxide concentration), and others, to predict the value of MEDV (median housing price). It involves installing Python, Spark, the findspark library, Numpy, and Jupyter.
The first problem is one of regression, trying to use the features to predict the label of home value.

By using the assembler to create the features column, you can represent the values in a table.

Afterward, you can split the data into training and testing examples to create a model and then evaluate its performance.


If you want more practice, this additional tutorial employs Spark to build a decision-tree classifier to predict automobile gas mileage. As you can see, MLlib offers fast and dynamic processing, but can consume a lot of expensive memory.
Looking for more information about Spark? Check out our guide to training a very large model using Spark.
More options
Besides these frameworks, there are others that you can explore as time permits, like:
- RAPIDS is a suite of NVIDIA software libraries built on CUDA-X-AI, where you can perform end-to-end data science and analytics on GPUs. RAPIDS facilitates data preparation and supports multi-node, multi-GPU deployments for faster processing of large datasets.
- Torch is a machine learning scientific computing framework that uses the LuaJIT scripting language and C/CUDA implementation. It is very similar to PyTorch, as PyTorch is the Python implementation of Torch.
- Caffe is a Berkeley AI Research BSD-authorized C++ library with Python interface, suitable for deep learning. It supports easy image recognition, but its limited architecture lacks versatility with regard to use cases.
- Theano is a Python deep learning library developed at the University of Montreal, which specializes in deep neural network algorithms. It can execute mathematical calculations with multidimensional arrays using CPU and GPU, as well as support libraries like Keras, Lasagne, and Blocks; however, it is not as popular as TensorFlow and lacks some common data visualization functionalities and monitoring/debugging tools.
Since you’re here…Are you interested in this career track? Investigate with our free guide to what a data professional actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp which will help you land a job or your tuition back!